实例化¶
更新记录
2023/9/1 增加该扩展文档
2023/9/1 增加
教程章节2023/9/1 增加
多实例章节2023/9/1 增加
多物体章节2023/9/4 更新
多实例章节2023/9/4 增加
设备内存分配器 (DMA)章节2023/9/4 增加
hello_vulkan.h章节2023/9/4 增加
hello_vulkan.cpp章节2023/9/4 增加
结果章节2023/9/4 增加
VMA :Vulkan 内存分配器章节2023/9/4
VMA :Vulkan 内存分配器章节下增加hello_vulkan.h章节2023/9/4
VMA :Vulkan 内存分配器章节下增加hello_vulkan.cpp章节2023/9/7 提供
Turbo实现开源示例2023/9/7 更新
多实例章节,增加注解。2023/9/7 更新
多物体章节,增加注解。
Turbo 引擎中对该教程的实现示例
Turbo 引擎对该教程进行了实现,具体如下:
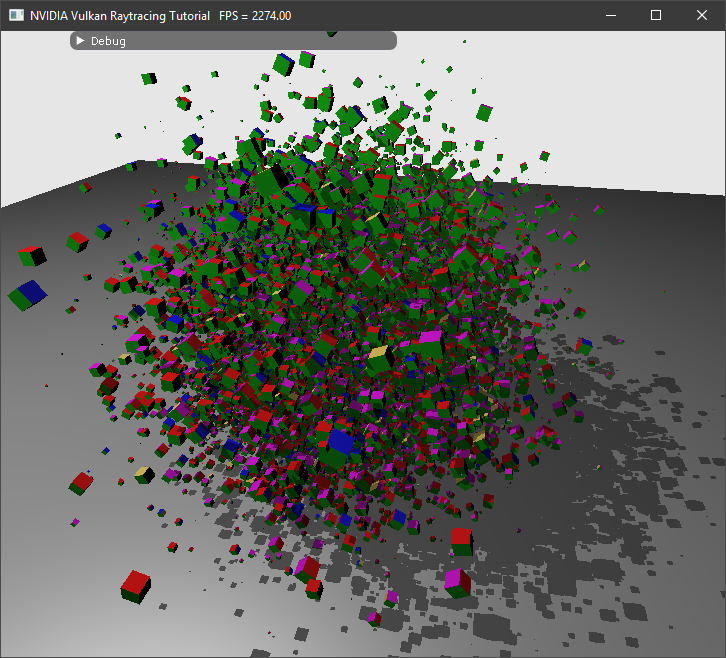
实例化结果示意图¶
教程¶
该教程为 Vulkan 光线追踪教程 的扩展。
光线追踪可以一次性处理有很多物体的实体。对于一个实体,一个顶层加速结构中可以包含不同的底层加速结构。然而,当我们有很多不同的物体时,在内存分配上就会遇到问题。很多 Vulkan 驱动实现只支持最多 4096 个分配,当我们的程序每个物体创建 4 次分配(顶点,索引和材质),其中还包括一个底层加速结构。这就意味着当我们创建 1000 个物体时,这将会触及到分配上限。
多实例¶
注解
该方式实现的多实例的本质是通过创建多个 VkAccelerationStructureInstanceKHR 并引用相同的底层加速结构(模型)实现的。
首先,让我们先来看看使用零星的几个物体构建多个实例的场景长什么样。
在 main.cpp 中,增加如下头文件:
#include <random>
之后将 main() 中的 helloVk.loadModel 调用更改如下,这将会创建 cube 和 cube_multi 的实例。
// 加载模型
helloVk.loadModel(nvh::findFile("media/scenes/cube.obj", defaultSearchPaths, true));
helloVk.loadModel(nvh::findFile("media/scenes/cube_multi.obj", defaultSearchPaths, true));
helloVk.loadModel(nvh::findFile("media/scenes/plane.obj", defaultSearchPaths, true));
std::random_device rd; // 用于获取用于随机引擎的种子
std::mt19937 gen(rd()); // rd() 的标准 mersenne_twister_engine 种子
std::normal_distribution<float> dis(1.0f, 1.0f);
std::normal_distribution<float> disn(0.05f, 0.05f);
for(uint32_t n = 0; n < 2000; ++n)
{
float scale = fabsf(disn(gen));
nvmath::mat4f mat =
nvmath::translation_mat4(nvmath::vec3f{dis(gen), 2.0f + dis(gen), dis(gen)});
mat = mat * nvmath::rotation_mat4_x(dis(gen));
mat = mat * nvmath::scale_mat4(nvmath::vec3f(scale));
helloVk.m_instances.push_back({mat, n % 2});
}
备注
这将会创建 3 个 OBJ 模型和相应的实体,之后将会随机创建 2000 个绿色或各面异色的方盒实例。
小技巧
此种方式是通过创建少数底层加速结构作为几何物体,之后创建大量顶层加速结构的实体来实现的实例化。
多物体¶
注解
该方式实现的多实例的本质是通过创建多个底层加速结构(模型)实现的。当创建的底层加速结构过多时大概率会触及 Vulkan 资源分配的上限。
创建多个物体,而不是创建多个实例。
将上面的代码替换成如下:
std::random_device rd; // 用于获取用于随机引擎的种子
std::mt19937 gen(rd()); // rd() 的标准 mersenne_twister_engine 种子
std::normal_distribution<float> dis(1.0f, 1.0f);
std::normal_distribution<float> disn(0.05f, 0.05f);
for(int n = 0; n < 2000; ++n)
{
float scale = fabsf(disn(gen));
nvmath::mat4f mat = nvmath::translation_mat4(nvmath::vec3f{dis(gen), 2.0f + dis(gen), dis(gen)});
mat = mat * nvmath::rotation_mat4_x(dis(gen));
mat = mat * nvmath::scale_mat4(nvmath::vec3f(scale));
helloVk.loadModel(nvh::findFile("media/scenes/cube_multi.obj", defaultSearchPaths, true), mat);
}
helloVk.loadModel(nvh::findFile("media/scenes/plane.obj", defaultSearchPaths, true));
这样也是可以工作的,但是在加载 1363 个物体之后将会输出如下错误。 创建 1363 个之后的所有物体将会失败。
Error |
Number of currently valid memory objects is not less than the maximum allowed (4096). |
|---|---|
Note |
This is the best case; the application can run out of memory and crash if substantially more objects are created (e.g. 20,000) |
小技巧
此种方式是通过创建大量数底层加速结构作为几何物体,之后创建少数的顶层加速结构的实体来实现的实例化。
设备内存分配器 (DMA)¶
如上分配问题可通过使用内存分配器得到解决。
hello_vulkan.h¶
在 hello_vulkan.h , 在文件顶部增加如下宏定义,用于声明使用何种分配器。
// 选择使用何种分配器
#define ALLOC_DMA
//#define ALLOC_DEDICATED
//#define ALLOC_VMA
替换缓存和纹理的定义并包含正确的分配器。
#if defined(ALLOC_DMA)
#include <nvvk/memallocator_dma_vk.hpp>
using Allocator = nvvk::ResourceAllocatorDma;
#elif defined(ALLOC_VMA)
#include <nvvk/memallocator_vma_vk.hpp>
using Allocator = nvvk::ResourceAllocatorVma;
#else
using Allocator = nvvk::ResourceAllocatorDedicated;
#endif
并将 ResourceAllocatorDedicatednvvk:: 替换成通用分配类型。
Allocator m_alloc;
hello_vulkan.cpp¶
在源文件中不需要做任何修改,所有的分配器都使用相同的 API 。
结果¶
相对于成千的分配,该示例仅使用 14 个内存分配。
备注
下图所示的其中一些分配是 Dear ImGui 分配的,并不是 DMA 分配的。其中的 14 个蓝边框的内存为 DMA 分配的。
内存分配示意图¶
最后,在 Nsight Graphics 中 Vulkan 的设备内存如下:
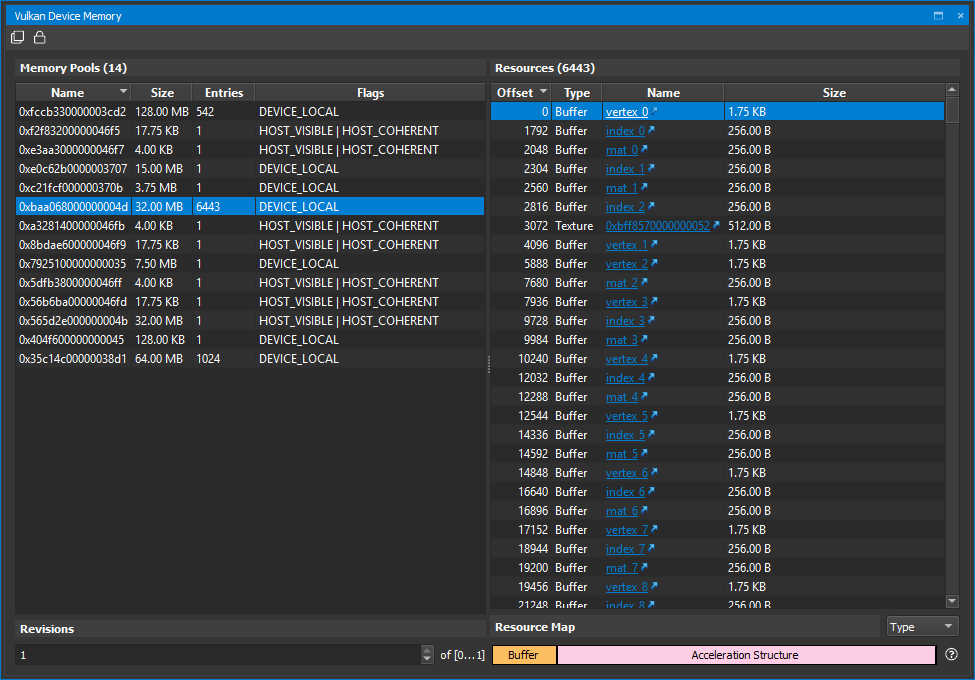
Vulkan 设备内存示意图¶
VMA :Vulkan 内存分配器¶
我们同样可以使用 AMD 的 Vulkan Memory Allocator ( VMA )。
VMA 是 nvpro_core/third_party 下的一个子模块。
VMA 使用的是专用内存,所以您需要在 main.cpp 增加如下扩展来创建上下文。
contextInfo.addDeviceExtension(VK_KHR_BIND_MEMORY_2_EXTENSION_NAME);
hello_vulkan.h¶
激活 VMA 的宏定义
#define ALLOC_VMA
hello_vulkan.cpp¶
VMA 需要获取函数的具体实现并且在之后的代码中只允许被定义一遍,并且需要在 #include "hello_vulkan.h" 之前定义:
#define VMA_IMPLEMENTATION
为确认是否使用 VMA 分配器,在 VMAMemoryAllocator::allocMemory() 处打个断点。