NVIDIA Vulkan 光线追踪教程¶
更新记录
2023/5/15 创建本文
2023/5/15 增加
介绍章节2023/5/15 增加
配置环境章节2023/5/15 增加
生成解决方案章节2023/5/17 增加
生成解决方案章节2023/5/17 增加
编译和运行章节2023/5/17 增加
开始步入光线追踪章节2023/5/18 更新
开始步入光线追踪章节2023/5/18 增加
加速结构章节2023/5/20 更新
加速结构章节2023/5/20 增加
底层加速结构章节2023/5/20 增加
帮助类细节:RaytracingBuilder::buildBlas()章节2023/5/21 更新
帮助类细节:RaytracingBuilder::buildBlas()章节2023/5/22 更新
帮助类细节:RaytracingBuilder::buildBlas()章节2023/5/22 增加
cmdCreateBlas章节2023/5/22 增加章节号
2023/5/23 更新
5.1 底层加速结构章节2023/5/23 更新
5.1.1 帮助类细节:RaytracingBuilder::buildBlas()章节2023/5/23 更新
5.1.1.1 cmdCreateBlas章节2023/5/23 增加
5.1.1.2 cmdCompactBlas章节2023/5/24 更新
5.1.1.2 cmdCompactBlas章节2023/5/24 更新
5.1.1 帮助类细节:RaytracingBuilder::buildBlas()章节2023/5/24 增加
5.2 顶层加速结构章节2023/5/24 更新
5 加速结构章节2023/5/25 更新
5.2 顶层加速结构章节2023/5/25 增加
5.2.1 帮助类细节:RaytracingBuilder::buildTlas()章节2023/5/26 更新
5.2.1 帮助类细节:RaytracingBuilder::buildTlas()章节2023/5/26 增加
5.3 main章节2023/5/26 增加
6 光线追踪描述符集(Descriptor Set)章节2023/5/26 增加
6.1 增加场景的描述符集章节2023/5/27 更新
6.1 增加场景的描述符集章节2023/5/27 增加
6.2 描述符更新章节2023/5/27 增加
6.3 main章节2023/5/27 增加
7 光线追踪管线章节2023/5/28 更新
7 光线追踪管线章节2023/5/28 增加
7.1 增加着色器章节2023/5/29 更新
7.1 增加着色器章节2023/5/30 更新
7 光线追踪管线章节,增加任意命中着色器中候选交点说明2023/5/30 更新
7.1 增加着色器章节2023/5/30 增加
8 着色器绑定表章节2023/5/31 更新
8 着色器绑定表章节2023/5/31 增加
8.1 句柄章节2023/6/1 更新
5.1.1 帮助类细节:RaytracingBuilder::buildBlas()章节,修改我们将底层加速结构分割并使用多个大约 256MB 的内存块创建2023/6/1 更新
8.1 句柄章节2023/6/2 更新
8.1 句柄章节2023/6/2 增加
8.2 main章节2023/6/2 增加
9 光线追踪章节2023/6/2 增加
10 开始追踪章节2023/6/2 增加
10.1 main章节2023/6/3 增加
11 相机矩阵章节2023/6/3 增加
11.1 光线生成(raytrace.rgen)章节2023/6/3 增加
11.2 未命中着色器(raytrace.miss)章节2023/6/3 增加
12 简单光照章节2023/6/4 更新
12 简单光照章节2023/6/4 增加
12.1 最近命中着色器(raytrace.rchit)章节2023/6/4 增加
13 简单材质章节2023/6/4 增加
13.1 raytrace.rchit章节2023/6/4 增加
13.2 main章节2023/6/4 增加
14 阴影章节2023/6/4 增加
14.1 createRaytracingPipeline章节2023/6/4 增加
14.2 createRtShaderBindingTable章节2023/6/4 增加
14.3 createRtDescriptorSet章节2023/6/4 增加
14.4 raytrace.rchit章节2023/6/4 增加
15 拓展延伸章节2023/6/4 初步翻译完成
2023/8/23 提供
Turbo实现开源示例2023/8/24 增加
任意命中着色器(Any Hit Shaders)教程扩展文档2023/8/24 增加
相机抖动抗锯齿教程扩展文档2023/9/1 增加
实例化文档链接2023/9/7 增加
反射文档链接2023/9/12 增加
多重最近命中着色器文档链接2023/9/15 更新
8.1 句柄修改文字错误2023/9/15 更新
8 着色器绑定表添加随笔链接2023/9/20 增加
动态更新文档链接2023/10/7 增加
相交着色器文档链接2023/10/16 增加
可调用着色器文档链接2023/10/21 增加
光线查询文档链接2023/10/21 增加
glTF 场景文档链接
Turbo 引擎中对该教程的实现示例
Turbo 引擎对该教程进行了实现,具体如下:
VulkanKHRRayTracingTest :提供光栅化和实时光追两种渲染方式切换。 示例视频
VulkanKHRRayTracingTestForLighting :提供实时光追的
Phong光照模型渲染。 示例视频VulkanKHRRayTracingTestForLightingShadow :提供实时光追光照中的阴影渲染。 示例视频
VulkanKHRRayTracingTestForLightingShadowWithTexture :提供实时光追光照中的纹理采样。 示例视频
本文所提供的的代码和文档聚焦于使用 VK_KHR_ray_tracing_pipeline 扩展展示一个基础光追示例。
该教程从一个基于 Vulkan 开发的基础程序开始,并且提供一步步的介绍去修改和增加函数和功能。
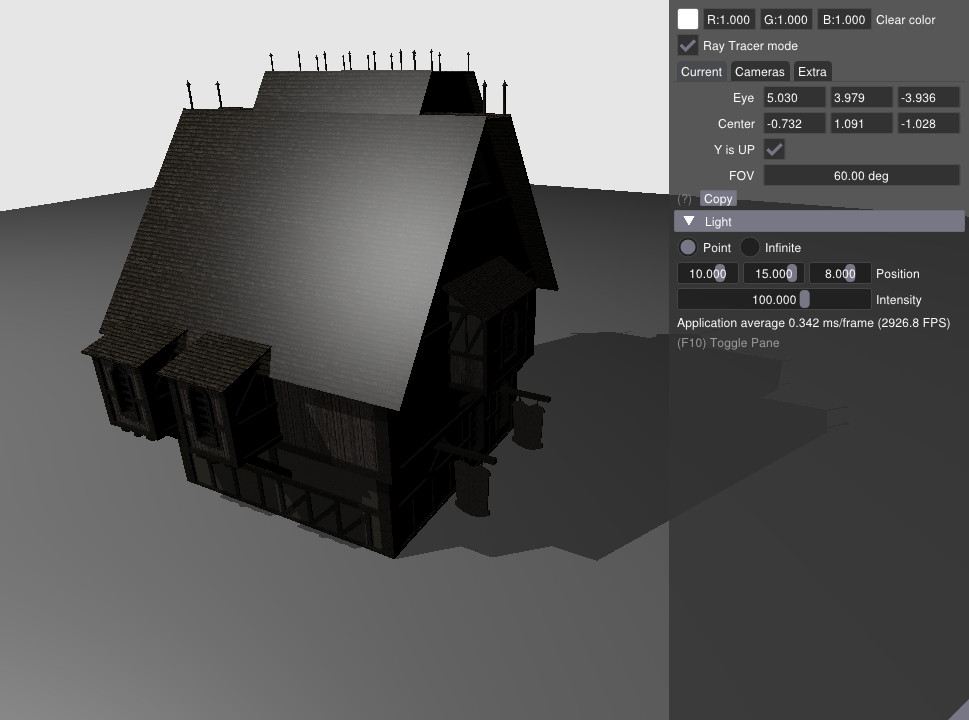
最终结果¶
1 介绍¶
本教程重点介绍将光线跟踪添加到现有 Vulkan 应用中的步骤,并假设您对 Vulkan 有一定的了解。
对于像交换链管理、 Render Pass 等常见的组件已经封装在了 C++ API helpers 和
英伟达的 nvpro-samples 框架中。这个框架包含很多高级示例,对于 Vulkan 和 OpenGL 最佳实践也在其中。
我们同时使用一个助手去生成光追的加速结构,我们会在本文中对其进行详细说明。
备注
出于教育的目的,所有的代码都在分散一些很小的文件中。要将这些结合起来需要额外的抽象层级。
2 配置环境¶
推荐的方式是通过 nvpro-samples 的 build_all 脚本去下载包括 NVVK 在内的工程。
在命令行中,从 https://github.com/nvpro-samples/build_all 中克隆 nvpro-samples/build_all 仓库:
git clone https://github.com/nvpro-samples/build_all.git
之后打开 build_all 文件夹并执行 clone_all.bat ( Windows ) 或 clone_all.sh ( Linux )。
如果你希望克隆尽可能少的仓库,打开命令行,并执行如下指令,这将只克隆需要的仓库:
git clone --recursive --shallow-submodules https://github.com/nvpro-samples/nvpro_core.git
git clone https://github.com/nvpro-samples/vk_raytracing_tutorial_KHR.git
2.1 生成解决方案¶
对于存储构建生成的解决方案,最经典的是在工程主目录下创建一个 build 文件夹。您可以是使用 CMake-GUI 或者如下指令生成目标工程:
cd vk_raytracing_tutorial_KHR
mkdir build
cd build
cmake ..
备注
如果您没有使用 Visual Studio 2019 或者更高版本,请确保 Visual Studio 中目标平台选择的是 x64 平台。
对于 Visual Studio 2019 来说默认是 x64 平台,但老版本就不一定了。
2.2 工具安装¶
我们需要一张支持 VK_KHR_ray_tracing_pipeline 扩展的显卡。对于英伟达的图形卡,您需要最起码是 2021年 或之后的 Vulkan驱动 。
该工程最低需要 Vulkan SDK 的版本为 1.2.161。该工程是使用 1.2.182.0 进行测试的。
3 编译和运行¶
打开位于 build 目录下的解决方案,之后编译并运行 vk_ray_tracing__before_KHR 。
该示例将会是此教程的示例起点。这是一个用于加载 OBJ 文件并使用 Vulkan 光栅化渲染他们的小框架。您可以通过阅读 Base Overview 来纵观该示例是如何实现的。
我们将使用这个框架加载几何体并且渲染场景来实现光线追踪。

首次执行¶
接下来的步骤将是修改 vk_ray_tracing__before_KHR 使其支持光线追踪。该教程修改后的最终结果将是同 vk_ray_tracing__simple_KHR 一样。如果开发过程发生错误
可以看看该工程。
vk_ray_tracing__simple_KHR 工程将会作为额外教程的起点进行开发讲解。
4 开始步入光线追踪¶
首先进入 main.cpp 文件的 main 函数,找到使用 nvvk::ContextCreateInfo 设置需要的 Vulkan 扩展。为了激活使用光线追踪,我们需要 VK_KHR_ACCELERATION_STRUCTURE 和 VK_KHR_RAY_TRACING_PIPELINE 两个扩展。这两个扩展
还依赖于其他扩展,如下是所有需要激活的扩展。
// #VKRay: 激活光线追踪扩展
VkPhysicalDeviceAccelerationStructureFeaturesKHR accelFeature{VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_ACCELERATION_STRUCTURE_FEATURES_KHR};
contextInfo.addDeviceExtension(VK_KHR_ACCELERATION_STRUCTURE_EXTENSION_NAME, false, &accelFeature); // 用于构建加速结构
VkPhysicalDeviceRayTracingPipelineFeaturesKHR rtPipelineFeature{VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_RAY_TRACING_PIPELINE_FEATURES_KHR};
contextInfo.addDeviceExtension(VK_KHR_RAY_TRACING_PIPELINE_EXTENSION_NAME, false, &rtPipelineFeature); // 用于 vkCmdTraceRaysKHR
contextInfo.addDeviceExtension(VK_KHR_DEFERRED_HOST_OPERATIONS_EXTENSION_NAME); // 光线追踪光线的依赖
在这些代码背后,其帮助我们选择一个支持激活 VK_KHR_* 扩展的物理设备,之后在调用 vkCreateDevice 之前将 VkPhysicalDevice*FeaturesKHR 结构体插入 VkDeviceCreateInfo 的 pNext 链中。
这将激活光线追踪特性并且获取有关设备对于光线追踪的能力。如果你对背后的原理好奇,可与预览 Vulkan 上下文封装 Context::initInstance() 。
加载函数指针
与 OpenGL 一样,当在 Vulkan 中使用扩展时,您需要使用 vkGetInstanceProcAddr 和 vkGetDeviceProcAddr 手动加载扩展函数指针。该示例的 nvvk::Context 类在内部使用魔法已经为您做好了,对于获取 Vulkan 的 C 语言的 API 可以通过调用 load_VK_EXTENSIONS 获取。
在 hello_vulkan.h 中的 HelloVulkan 类中,增加一个初始化函数和用于存储 GPU 的光追属性的成员变量。
// #VKRay
void initRayTracing();
VkPhysicalDeviceRayTracingPipelinePropertiesKHR m_rtProperties{VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_RAY_TRACING_PIPELINE_PROPERTIES_KHR};
在 hello_vulkan.cpp 结尾增加 initRayTracing() 函数体,该函数将会使用扩展查询 GPU 的光追属性。特别是对于获取最大递归深度的属性,例如对于单个光线可调用操作的嵌套式追踪数量。其可以看做场景中的单条光线递归路径追踪中可以反弹的次数。
需要注意的是,为了性能考量,递归应该尽量保持最小,这有利于循环执行。这也会查询之后章节创建着色器绑定表所需要的着色器头部大小。
// 初始化Vulkan光线追踪
// #VKRay
void HelloVulkan::initRayTracing()
{
// 设置光追属性
VkPhysicalDeviceProperties2 prop2{VK_STRUCTURE_TYPE_PHYSICAL_DEVICE_PROPERTIES_2};
prop2.pNext = &m_rtProperties;
vkGetPhysicalDeviceProperties2(m_physicalDevice, &prop2);
}
4.1 main¶
在 main.cpp 的 main() 函数中,我们在 helloVk.updateDescriptorSet() 之后调用初始化函数。
// #VKRay
helloVk.initRayTracing();
练习
当执行该程序时,您可以在 initRayTracing() 函数出打个断点查看光追属性数据。在 Quadro RTX 6000 设备上,
最大的递归深度是 31 ,着色器组处理组的大小是 16。
5 加速结构¶
为了提高效率,光线追踪使用加速结构( acceleration structure ( AS ) )组织几何体,这样在渲染时将减少光线-三角形求交测试的次数。该结构在硬件上使用经典的层级数据结构存储,但给用户提供可接触的层级只有
两级:一个顶层加速结构 ( top-level acceleration structure ( TLAS ) )可以引用任意数量的底层加速结构 ( bottom-level acceleration structures ( BLAS ) )。对于可以支持多少个顶层加速结构,
可通过 VkPhysicalDeviceAccelerationStructurePropertiesKHR::maxInstanceCount 获取到。通常一个底层加速结构对应场景中一个单独的 3D 模型,并且一个顶层加速结构通过每一个单独的底层加速结构所对应的的位置(使用 3×4 的变换矩阵)
构建场景。
底层加速结构存储确切具体的顶点数据,底层加速结构使用一个或多个顶点缓存( vertex buffers )构建,每一个顶点缓存都会有自己的变换矩阵(这与顶层加速结构的矩阵进行区分),这样我们就可以在一个底层加速结构中存储多个有位置数据的模型。
备注
如果一个物体在同一个底层加速结构中实例化多次,他们的几何体数据将会进行复制。这对于提高一些静态,未实例化的场景的性能特别有帮助。 据经验来说,底层加速结构越少越好。
顶层加速结构可以包含多个物体的实体( instance ),每一个实体都会有自己的变换矩阵并且引用一个具体的底层加速结构。我们将会从一个底层加速结构和一个单位矩阵的顶层加速结构实例开始实现。

加速结构¶
该教程将会加载一个 OBJ 文件,并将其索引、顶点和材质数据存储到 ObjModel 数据结构中。该模型同时引用一个 ObjInstance 数据结构,其中包含用于特定实体的变换矩阵。对于光线追踪, ObjModel 和一系列的 ObjInstances 将在之后分别用于构建底层加速结构和顶层加速结构。
为了假话光线追踪,我们使用一个帮助类,用于充当一个顶层加速结构和多个底层加速结构的容器,并且提供构建加速结构的接口函数。在 hello_vulkan.h 的头文件中包含 raytrace_vkpp 帮助类。
// #VKRay
#include "nvvk/raytraceKHR_vk.hpp"
之后我们可以在 HelloVulkan 类中增加该类型的成员变量。
nvvk::RaytracingBuilderKHR m_rtBuilder;
并且在 initRaytracing() 末尾进行初始化。
m_rtBuilder.setup(m_device, &m_alloc, m_graphicsQueueIndex);
内存管理
该光追帮助类使用 nvvk/resourceallocator_vk.hpp 避免去管理 Vulkan 内存。其内部提供 nvvk::AccelKHR 类型,该类型包含 VkAccelerationStructureKHR 用于缓存创建和备份所需要的信息。
该资源可以使用不同的内存分配策略进行分配。在该教程中我们使用我们自己的 DMA 。其他的内存分配器也是可以使用的,
比如 Vulkan Memory Allocator(VMA) 或是专用内存分配器(比如一个 VkDeviceMemory 对应一个对象的策略,这种分配策略对于教学目的最容易理解,但是并不能用于产品开发)。
5.1 底层加速结构¶
构建底层加速器的第一步就是将 ObjModel 的几何数据转换成构建加速结构所需要的多个结构体中。我们使用 nvvk::RaytracingBuilderKHR::BlasInput 来维护所有的的结构体。
在 HelloVulkan 类中增加一个新函数:
auto objectToVkGeometryKHR(const ObjModel& model);
备注
objectToVkGeometryKHR() 函数返回类型为 nvvk::RaytracingBuilderKHR::BlasInput 但是这里我们使用 C++ 的 auto 来将返回值的类型推演交给编译器。
此函数内部将会填充三个结构体,这些结构体之后会用于构建加速结构( vkCmdBuildAccelerationStructuresKHR ) 。
VkAccelerationStructureGeometryTrianglesDataKHR:指向存有三角形的顶点,索引数据的缓存,以数组解析其中的数据(跨度,数据类型等)。VkAccelerationStructureGeometryKHR:使用集合类型的枚举(此例为三角形)和加速结构的构建flags将之前的加速结构的几何数据进行打包。这一步是需要的,因为VkAccelerationStructureGeometryTrianglesDataKHR是作为联合VkAccelerationStructureGeometryDataKHR的一部分而传入的(几何体也可以是实例,用于顶层加速结构的构建或者AABBs包围盒,这些该例程并没有涉及到)。VkAccelerationStructureBuildRangeInfoKHR:指示作为底层加速结构输入的几何体中的顶点数组源的索引。
对于 VkAccelerationStructureGeometryKHR 和 VkAccelerationStructureBuildRangeInfoKHR 分别为独立结构体
一个潜在的疑惑:为什么 VkAccelerationStructureGeometryKHR 和 VkAccelerationStructureBuildRangeInfoKHR 最终在构建加速结构时是单独的不同参数,但是却协同却定了顶点数据源的真正内存。打一个粗略的比方,这有点类似于 glVertexAttribPointer 定义的如何将一个缓存解析成顶点数组,并在 glDrawArrays 时确定顶点数组中到底那一部分需要绘制。
多个如上的结构体可以组建一个数组并可以用于构建一个底层加速结构。在该示例中,此数组的大小总是 1 。 每一个底层加速结构有多个几何体是因为加速结构会更加高效,他会将求交的物体在空间上进行合理的划分。对于那种巨大、单一且静态的物体组需要考虑构建加速结构。
备注
我们现在认为所有的物体都是不透明的,并以此为前提进行潜在的优化。更具体的说是禁用了任意命中着色器( anyhit shader )的调用,之后会细说。
struct VertexObj
{
nvmath::vec3f pos;
nvmath::vec3f nrm;
nvmath::vec3f color;
nvmath::vec2f texCoord;
}
//--------------------------------------------------------------------------------------------------
// 将一个OBJ模型转变成光追几何体用于构建底层加速结构
//
auto HelloVulkan::objectToVkGeometryKHR(const ObjModel& model)
{
// 底层加速结构的侯建需要数据的原内存地址
VkDeviceAddress vertexAddress = nvvk::getBufferDeviceAddress(m_device, model.vertexBuffer.buffer);
VkDeviceAddress indexAddress = nvvk::getBufferDeviceAddress(m_device, model.indexBuffer.buffer);
uint32_t maxPrimitiveCount = model.nbIndices / 3;
// 将缓存描述为VertexObj(顶点)数组
VkAccelerationStructureGeometryTrianglesDataKHR triangles{VK_STRUCTURE_TYPE_ACCELERATION_STRUCTURE_GEOMETRY_TRIANGLES_DATA_KHR};
triangles.vertexFormat = VK_FORMAT_R32G32B32_SFLOAT; // vec3 顶点位置数据
triangles.vertexData.deviceAddress = vertexAddress;
triangles.vertexStride = sizeof(VertexObj);
// 描述索引数据 (32-bit unsigned int)
triangles.indexType = VK_INDEX_TYPE_UINT32;
triangles.indexData.deviceAddress = indexAddress;
//当前transformData设置为null时代表是单位矩阵
//triangles.transformData = {};
triangles.maxVertex = model.nbVertices;
// 将之前的三角形设定成不透明
VkAccelerationStructureGeometryKHR asGeom{VK_STRUCTURE_TYPE_ACCELERATION_STRUCTURE_GEOMETRY_KHR};
asGeom.geometryType = VK_GEOMETRY_TYPE_TRIANGLES_KHR;
asGeom.flags = VK_GEOMETRY_OPAQUE_BIT_KHR;
asGeom.geometry.triangles = triangles;
// 整个数组都将用于构建底层加速结构
VkAccelerationStructureBuildRangeInfoKHR offset;
offset.firstVertex = 0;
offset.primitiveCount = maxPrimitiveCount;
offset.primitiveOffset = 0;
offset.transformOffset = 0;
// 我们的底层加速结构只用一个几何体描述,但可以使用更多几何体
nvvk::RaytracingBuilderKHR::BlasInput input;
input.asGeometry.emplace_back(asGeom);
input.asBuildOffsetInfo.emplace_back(offset);
return input;
}
顶点属性
在上面的代码中, VertexObj 结构体中第一个成员是位置数据,如果成员在任意位置,我们需要使用 offsetof 手动调整 vertexAddress 。对于加速结构的构建只需位置属性。之后我们将学习
在光追时绑定顶点缓存并使用其他顶点属性。
内存安全
BlasInput 作为一个花里胡哨的设备指针指向顶点缓存数据。对于帮助类中并没有顶点数据的拷贝或管理。对于该示例,我们假设所有的模型都在一开始加载并且直到创建底层加速结构时内存不会篡改并有效。
如果你是动态加载并且卸载一个大场景的一部分或者动态生成顶点数据,您需要做的是在构建加速结构时避免发生资源竞争。
在 HelloVulkan 类声明中,我们现在可以增加 createBottomLevelAS() 函数用于对每一个对象生成 nvvk::RaytracingBuilderKHR::BlasInput 并用于构建底层加速结构:
void createBottomLevelAS();
在批量创建所有的底层加速结构前,使用一个循环遍历所有的模型,并且填入 nvvk::RaytracingBuilderKHR::BlasInput 数组中。加速结构的结存将会根据帮助类中的构建顺序存储,这样他们可以直接使用索引进行引用。
void HelloVulkan::createBottomLevelAS()
{
// 底层加速结构 - 存储每个几何体中的图元
std::vector<nvvk::RaytracingBuilderKHR::BlasInput> allBlas;
allBlas.reserve(m_objModel.size());
for(const auto& obj : m_objModel)
{
auto blas = objectToVkGeometryKHR(obj);
// 每一个底层加速结构都可以增加多个几何体,但现在我们只添加一个
allBlas.emplace_back(blas);
}
m_rtBuilder.buildBlas(allBlas, VK_BUILD_ACCELERATION_STRUCTURE_PREFER_FAST_TRACE_BIT_KHR);
}
5.1.1 帮助类细节:RaytracingBuilder::buildBlas()¶
这个帮助函数可以在 raytraceKHR_vkpp.hpp 中找到:其可以在很多项目中重用,并且也是 nvpro-samples 中众多帮助类中的其中之一。该函数会对每一个 RaytracingBuilderKHR::BlasInput 生成一个底层加速结构。
创建一个底层加速结构需要如下元素:
VkAccelerationStructureBuildGeometryInfoKHR:创建并构建加速结构,其基于objectToVkGeometryKHR()中创建的VkAccelerationStructureGeometryKHR数组。VkAccelerationStructureBuildRangeInfoKHR:范围引用,与objectToVkGeometryKHR()中使用的相同。VkAccelerationStructureBuildSizesInfoKHR:创建加速结构所需要的大小和暂付缓存信息nvvk::AccelKHR:结果
暂付缓存
暂付缓存( scratch buffer ),是 Vulkan 对于内部缓存的优化。原本的内部缓存应由 Vulkan 驱动内部自身分配和管理,但是有些内部内存会经常性的更新,为了优化这一部分缓存, Vulkan 将这一部分
缓存交由用户分配管理,优化了内存使用和读写。 scratch 原本是抓挠之意,由于这部分内存时不时的要更新一下,像猫抓一样,所以叫 抓挠 缓存,实则是暂时交付给 Vulkan 驱动内部。
如上这些数据将存储到名为 BuildAccelerationStructure 结构体中用于简化创建。
在函数一开始,我们仅仅初始化我们之后需要的数据。
//--------------------------------------------------------------------------------------------------
// 使用BlasInput的数组创建所有的底层加速结构
// - input数组中的每一个BlasInput都对应一个底层加速结构
// - 底层加速结构的数量将会和input.size()一样
// - 创建的底层加速结构将会存储在m_blas(类型为std::vector<nvvk::AccelKHR>),并可以通过数组索引获取引用
// - 如果flag里设置了Compact位域,底层加速结构将会被压缩
//
void nvvk::RaytracingBuilderKHR::buildBlas(const std::vector<BlasInput>& input, VkBuildAccelerationStructureFlagsKHR flags)
{
m_cmdPool.init(m_device, m_queueIndex);
uint32_t nbBlas = static_cast<uint32_t>(input.size());
VkDeviceSize asTotalSize{0}; // 所有要分配的底层加速结构所需要的内存大小
uint32_t nbCompactions{0}; // 需要压缩的底层加速结构的数量
VkDeviceSize maxScratchSize{0}; // 最大的暂付缓存大小
接下来就是为每个底层加速结构构建 BuildAccelerationStructure ,用于引用几何体、构建范围、内存大小和暂付缓存大小。我们需要在每一次创建时都使用同一个暂付缓存,所以
我们需要留意需要的暂付缓存的最大大小,之后我们将使用该大小分配暂付缓存。
// 为构建加速结构指令准备必要信息
std::vector<BuildAccelerationStructure> buildAs(nbBlas);
for(uint32_t idx = 0; idx < nbBlas; idx++)
{
// 填充VkAccelerationStructureBuildGeometryInfoKHR的部分属性用于获取构建的大小
// 其他信息将会在createBlas时填入 (see #2)
buildAs[idx].buildInfo.type = VK_ACCELERATION_STRUCTURE_TYPE_BOTTOM_LEVEL_KHR;
buildAs[idx].buildInfo.mode = VK_BUILD_ACCELERATION_STRUCTURE_MODE_BUILD_KHR;
buildAs[idx].buildInfo.flags = input[idx].flags | flags;
buildAs[idx].buildInfo.geometryCount = static_cast<uint32_t>(input[idx].asGeometry.size());
buildAs[idx].buildInfo.pGeometries = input[idx].asGeometry.data();
// 设置范围信息
buildAs[idx].rangeInfo = input[idx].asBuildOffsetInfo.data();
// 获取创建加速结构所需的缓存和暂付缓存的大小
std::vector<uint32_t> maxPrimCount(input[idx].asBuildOffsetInfo.size());
for(auto tt = 0; tt < input[idx].asBuildOffsetInfo.size(); tt++)
maxPrimCount[tt] = input[idx].asBuildOffsetInfo[tt].primitiveCount; // Number of primitives/triangles
vkGetAccelerationStructureBuildSizesKHR(m_device, VK_ACCELERATION_STRUCTURE_BUILD_TYPE_DEVICE_KHR,
&buildAs[idx].buildInfo, maxPrimCount.data(), &buildAs[idx].sizeInfo);
// 统计合并必要的数据大小
asTotalSize += buildAs[idx].sizeInfo.accelerationStructureSize;
maxScratchSize = std::max(maxScratchSize, buildAs[idx].sizeInfo.buildScratchSize);
nbCompactions += hasFlag(buildAs[idx].buildInfo.flags, VK_BUILD_ACCELERATION_STRUCTURE_ALLOW_COMPACTION_BIT_KHR);
}
在遍历完所有的底层加速结构后,我们有了需要创建的暂付缓存最大的大小。
// 分配一个暂付缓存用于存储加速结构构建的临时数据
nvvk::Buffer scratchBuffer = m_alloc->createBuffer(maxScratchSize, VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT | VK_BUFFER_USAGE_STORAGE_BUFFER_BIT);
VkBufferDeviceAddressInfo bufferInfo{VK_STRUCTURE_TYPE_BUFFER_DEVICE_ADDRESS_INFO, nullptr, scratchBuffer.buffer};
VkDeviceAddress scratchAddress = vkGetBufferDeviceAddress(m_device, &bufferInfo);
接下来就是获取每一个底层加速结构的真正的大小。为了得到真正的大小,我们将使用 VK_QUERY_TYPE_ACCELERATION_STRUCTURE_COMPACTED_SIZE_KHR 类型获取。 如果我们想要在之后压缩加速结构该类型是需要的。默认的情况下, vkGetAccelerationStructureBuildSizesKHR 将会返回无任何优化(最糟糕)的内存大小。在压缩创建之后,真实占有的空间大小可以相对较小,并且在加速结构之后拷贝仅拷贝必要信息。这将会节省超过 50% 的设备内存使用。
// 创建一个用于获取每一个底层加速结构压缩的存储大小的查询队列
VkQueryPool queryPool{VK_NULL_HANDLE};
if(nbCompactions > 0) // 是否有压缩的需求?
{
assert(nbCompactions == nbBlas); // 不允许混合使用压缩与非压缩的底层加速结构(要么全都压缩,要么都不压缩)
VkQueryPoolCreateInfo qpci{VK_STRUCTURE_TYPE_QUERY_POOL_CREATE_INFO};
qpci.queryCount = nbBlas;
qpci.queryType = VK_QUERY_TYPE_ACCELERATION_STRUCTURE_COMPACTED_SIZE_KHR;
vkCreateQueryPool(m_device, &qpci, nullptr, &queryPool);
}
压缩
为了使用压缩,底层加速结构的 flags 必须包含 VK_BUILD_ACCELERATION_STRUCTURE_ALLOW_COMPACTION_BIT_KHR 位域。
Vulkan 允许使用一个命令缓存( command buffer )创建所有的底层加速结构,但是这可能会导致管线的停顿和潜在的创建问题。为了避免这些问题,我们将底层加速结构按照大约 256MB 为一批进行创建。如果我们有压缩的需求,我们将立即执行,从而限制所需的内存分配。
如下即为将底层加速结构分割创建,对于 cmdCreateBlas 和 cmdCompactBlas 函数将会一会儿细说。
256MB
并不是将一个占有巨大内存的加速结构分割成多个 256MB 的小内存块,而是每当一批加速结构的内存超过 256MB 的话,创建一个新的命令缓存负责该批加速结构的创建、构建和压缩。是将加速结构分散在不同的命令缓存中。
// 批量创建/压缩底层加速结构,这样可以存入有限的内存
std::vector<uint32_t> indices; // 底层加速结构创建对应的索引
VkDeviceSize batchSize{0};
VkDeviceSize batchLimit{256'000'000}; // 256 MB
for(uint32_t idx = 0; idx < nbBlas; idx++)
{
indices.push_back(idx);
batchSize += buildAs[idx].sizeInfo.accelerationStructureSize;
// 超过限值或是最后一个底层加速结构
if(batchSize >= batchLimit || idx == nbBlas - 1)
{
VkCommandBuffer cmdBuf = m_cmdPool.createCommandBuffer();
cmdCreateBlas(cmdBuf, indices, buildAs, scratchAddress, queryPool);
m_cmdPool.submitAndWait(cmdBuf);
if(queryPool)
{
VkCommandBuffer cmdBuf = m_cmdPool.createCommandBuffer();
cmdCompactBlas(cmdBuf, indices, buildAs, queryPool);
m_cmdPool.submitAndWait(cmdBuf); // 将命令缓存推送到队列执行并且调用vkQueueWaitIdle等待执行结束
// 销毁未压缩版本
destroyNonCompacted(indices, buildAs);
}
// 重置
batchSize = 0;
indices.clear();
}
}
创建的加速结构将会保存在 BuildAccelerationStructure 中,可以通过索引获取到。
// 存储所有创建的加速结构
for(auto& b : buildAs)
{
// b.as中的as即为创建的加速结构结果,类型为nvvk::AccelKHR
m_blas.emplace_back(b.as);
}
最后我们将会清空不再需要的对象和内存。
// 清空
vkDestroyQueryPool(m_device, queryPool, nullptr);
m_alloc->finalizeAndReleaseStaging();
m_alloc->destroy(scratchBuffer);
m_cmdPool.deinit();
5.1.1.1 cmdCreateBlas¶
//--------------------------------------------------------------------------------------------------
// 为buildAs数组中所有的BuildAccelerationStructure创建底层加速结构。
// BuildAccelerationStructure的数组是在buildBlas函数中构建的。
// indices的数组用于限值一次性创建底层加速结构的数量。
// 当压缩底层加速结构这将会限值内存量
void nvvk::RaytracingBuilderKHR::cmdCreateBlas(VkCommandBuffer cmdBuf,
std::vector<uint32_t> indices,
std::vector<BuildAccelerationStructure>& buildAs,
VkDeviceAddress scratchAddress,
VkQueryPool queryPool)
{
首先我们为了获取底层加速结构的真正的大小需要重置查询。
if(queryPool) // 用于查询压缩大小
vkResetQueryPool(m_device, queryPool, 0, static_cast<uint32_t>(indices.size()));
uint32_t queryCnt{0};
该函数将会根据索引数组中的索引创建所有对应的底层加速结构
for(const auto& idx : indices)
{
创建底层加速结构分两步:
创建加速结构:使用抽象内存分配器和之前获取的大小信息,调用
createAcceleration()函数来创建缓存和加速结构。构建加速结构:使用加速结构,暂付缓存和几何信息构建真正的底层加速结构。
这之后调用 m_alloc->createAcceleration 函数,该函数背后将按照查询到的加速结构的大小,并使用 VK_BUFFER_USAGE_ACCELERATION_STRUCTURE_STORAGE_BIT_KHR 和 VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT 两个缓存功能位域创建缓存( 由于之后创建顶层加速结构需要底层加速结构的地址,所以需要 VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT ),
并通过 VkAccelerationStructureCreateInfoKHR 设置目标 buffer 以此将分配的内存与加速结构进行绑定。而 buffer 和 image 在绑定内存上与加速结构不同,对于 buffer 和 image 其在 Vk* 的句柄分配和内存绑定是分开独立进行的,而加速结构是在通过 vkCreateAccelerationStructureKHR 创建时同时创建和绑定内存。
// 真正的缓存分配和加速结构创建
VkAccelerationStructureCreateInfoKHR createInfo{VK_STRUCTURE_TYPE_ACCELERATION_STRUCTURE_CREATE_INFO_KHR};
createInfo.type = VK_ACCELERATION_STRUCTURE_TYPE_BOTTOM_LEVEL_KHR;
createInfo.size = buildAs[idx].sizeInfo.accelerationStructureSize; // 将用于内存分配
buildAs[idx].as = m_alloc->createAcceleration(createInfo);
NAME_IDX_VK(buildAs[idx].as.accel, idx);
NAME_IDX_VK(buildAs[idx].as.buffer.buffer, idx);
// BuildInfo #2 part
buildAs[idx].buildInfo.dstAccelerationStructure = buildAs[idx].as.accel; // 设置构建的目标加速结构
buildAs[idx].buildInfo.scratchData.deviceAddress = scratchAddress; // 所有的构建都使用同一个暂付缓存
// 构建底层加速结构
vkCmdBuildAccelerationStructuresKHR(cmdBuf, 1, &buildAs[idx].buildInfo, &buildAs[idx].rangeInfo);
注意在每次调用构建之后需要设置栅栏( barrier ):为了方便起见,在构建时重复使用暂付缓存,所以这里需要确保在开始一个新的构建前,之前的构建已经完成。按理来说,我们应该使用暂付缓存的不同部分以此来同时创建多个底层加速结构。
// 一旦暂付缓存被重复使用, 我们需要一个栅栏用于确保之前的构建已经结束才开始构建下一个
VkMemoryBarrier barrier{VK_STRUCTURE_TYPE_MEMORY_BARRIER};
barrier.srcAccessMask = VK_ACCESS_ACCELERATION_STRUCTURE_WRITE_BIT_KHR;
barrier.dstAccessMask = VK_ACCESS_ACCELERATION_STRUCTURE_READ_BIT_KHR;
vkCmdPipelineBarrier(cmdBuf, VK_PIPELINE_STAGE_ACCELERATION_STRUCTURE_BUILD_BIT_KHR,
VK_PIPELINE_STAGE_ACCELERATION_STRUCTURE_BUILD_BIT_KHR, 0, 1, &barrier, 0, nullptr, 0, nullptr);
之后我们查询需要的加速结构大小
if(queryPool)
{
// 查询真正需要的内存数量,用于压缩
vkCmdWriteAccelerationStructuresPropertiesKHR(cmdBuf, 1, &buildAs[idx].buildInfo.dstAccelerationStructure,
VK_QUERY_TYPE_ACCELERATION_STRUCTURE_COMPACTED_SIZE_KHR, queryPool, queryCnt++);
}
}
}
尽管该方法可以很好的保持所有的底层加速结构的独立性,但构建很多底层加速结构将需要大量的暂付缓存并同时启动多个构建。当前的这个教程并没有使用可以大量减少加速结构内存的压缩策略。有关这两个方面将会在未来的高级教程中有所体现。
5.1.1.2 cmdCompactBlas¶
当位域( flag )设置了压缩的话将会进入 cmdCompactBlas,将底层加速结构压缩进内存,这一部分功能是可选的。我们将会等待所有的底层加速结构构建完成之后再将其拷贝至合适的内存空间中。这就是为什么我们要在调用 cmdCompactBlas 函数之前调用 m_cmdPool.submitAndWait(cmdBuf) 。
//--------------------------------------------------------------------------------------------------
// 使用查询队列查询到的大小创建新的缓存和加速结构并替换
void nvvk::RaytracingBuilderKHR::cmdCompactBlas(VkCommandBuffer cmdBuf,
std::vector<uint32_t> indices,
std::vector<BuildAccelerationStructure>& buildAs,
VkQueryPool queryPool)
{
大体上来说,压缩流程如下:
获取查询到的数据(压缩大小)
使用较小的大小创建一个新的加速结构
将之前的加速结构拷贝到新创建的加速结构中
将之前的加速结构销毁
uint32_t queryCtn{0};
std::vector<nvvk::AccelKHR> cleanupAS; // 准备将之前的加速结构销毁
// 获取查询到的压缩大小
std::vector<VkDeviceSize> compactSizes(static_cast<uint32_t>(indices.size()));
vkGetQueryPoolResults(m_device, queryPool, 0, (uint32_t)compactSizes.size(), compactSizes.size() * sizeof(VkDeviceSize),
compactSizes.data(), sizeof(VkDeviceSize), VK_QUERY_RESULT_WAIT_BIT);
for(auto idx : indices)
{
buildAs[idx].cleanupAS = buildAs[idx].as; // 设置要销毁的加速结构
buildAs[idx].sizeInfo.accelerationStructureSize = compactSizes[queryCtn++]; // 使用压缩大小
// 创建压缩版本的加速结构
VkAccelerationStructureCreateInfoKHR asCreateInfo{VK_STRUCTURE_TYPE_ACCELERATION_STRUCTURE_CREATE_INFO_KHR};
asCreateInfo.size = buildAs[idx].sizeInfo.accelerationStructureSize;
asCreateInfo.type = VK_ACCELERATION_STRUCTURE_TYPE_BOTTOM_LEVEL_KHR;
buildAs[idx].as = m_alloc->createAcceleration(asCreateInfo);
NAME_IDX_VK(buildAs[idx].as.accel, idx);
NAME_IDX_VK(buildAs[idx].as.buffer.buffer, idx);
// 将之前的底层加速结构拷贝至压缩版本中
VkCopyAccelerationStructureInfoKHR copyInfo{VK_STRUCTURE_TYPE_COPY_ACCELERATION_STRUCTURE_INFO_KHR};
copyInfo.src = buildAs[idx].buildInfo.dstAccelerationStructure;
copyInfo.dst = buildAs[idx].as.accel;
copyInfo.mode = VK_COPY_ACCELERATION_STRUCTURE_MODE_COMPACT_KHR;
vkCmdCopyAccelerationStructureKHR(cmdBuf, ©Info);
}
}
5.2 顶层加速结构¶
顶层加速结构是描述光追场景的入口,并且存有所有的实体。在 HelloVulkan 类中增加一个新成员方法:
void createTopLevelAS();
我们使用 VkAccelerationStructureInstanceKHR 代表一个实体,其内部有用于与 buildBlas 中创建的底层加速结构相关联的变换矩阵( transform ),并且还包括一个实体 ID 号,可以在着色器中通过 gl_InstanceCustomIndex 获取到,用于表示着色器中调用被击中对象组中的索引( VkAccelerationStructureInstanceKHR::instanceShaderBindingTableRecordOffset 在帮助类中也叫 hitGroupId )。
gl_InstanceID
不要将 gl_InstanceID 和 gl_InstanceCustomIndex 搞混。 gl_InstanceID 仅仅用于表示在顶层加速结构内实体集中被击中的实体索引。
在本教程中,我们可以暂时忽略自定义索引( gl_InstanceCustomIndex ),因为其值将会与 gl_InstanceID 相等( gl_InstanceID 用于表示与当前光线相交的实体索引,目前该索引值与 i 值相同)。在之后的例子中该值将会不同。
备注
这个
i突然冒出来,不知所云。估计应该是着色器中的实体索引:layout(set = 1, binding = eObjDescs, scalar) buffer objDesc_ {ObjDesc i[];} objDesc;
gl_InstanceCustomIndex。根据 GLSL标准 中的描述, 其是用于描述:与当前光线相交的实体中应用自定义的值,该值为32位,使用低24位,高8位是0。使用时一般写作gl_InstanceCustomIndexEXT。gl_InstanceID根据 GLSL标准 中的描述, 其是用于描述:与当前光线相交的实体的索引。
详情可参考该 Issue 。
索引和命中组( hit groups )概念贯穿光追管线和着色器绑定表,将会在后面介绍并用于在运行时选择确认哪些着色器被调用。就目前来说我们整个场景中只会使用一个命中组,所以命中组的索引将一直是 0 。最终实体也许会指示剔除选项,比如使用 VkGeometryInstanceFlagsKHR flags 剔除背面。在此例子中我们为了简单和独立输入模型决定禁用剔除。
一旦所有的实体对象创建完成,我们将会构建顶层加速结构,构建器比较喜欢生成光追性能友好的顶层加速结构(比如加速结构的大小不是首要考虑的)。
void HelloVulkan::createTopLevelAS()
{
std::vector<VkAccelerationStructureInstanceKHR> tlas;
tlas.reserve(m_instances.size());
for(const HelloVulkan::ObjInstance& inst : m_instances)
{
VkAccelerationStructureInstanceKHR rayInst{};
rayInst.transform = nvvk::toTransformMatrixKHR(inst.transform); // 该实体的位置
rayInst.instanceCustomIndex = inst.objIndex; // gl_InstanceCustomIndexEXT
rayInst.accelerationStructureReference = m_rtBuilder.getBlasDeviceAddress(inst.objIndex);
rayInst.flags = VK_GEOMETRY_INSTANCE_TRIANGLE_FACING_CULL_DISABLE_BIT_KHR;
rayInst.mask = 0xFF; // 只有当 rayMask & instance.mask != 0 成立方为命中
rayInst.instanceShaderBindingTableRecordOffset = 0; // 对于所有的对象我们将使用相同的命中组
tlas.emplace_back(rayInst);
}
m_rtBuilder.buildTlas(tlas, VK_BUILD_ACCELERATION_STRUCTURE_PREFER_FAST_TRACE_BIT_KHR);
}
m_instances 的 inst.transform 和 inst.objIndex
都是在一开始调用 loadModel(const std::string& filename, nvmath::mat4f transform = nvmath::mat4f(1)) 函数加载模型时设置好的,对于 inst.transform 设置的是默认参数 nvmath::mat4f(1) 也就是单位矩阵。
对于 inst.objIndex 设置的是读取的第几个模型作为对象索引。每一个模型对应 m_instances 数组中的一个元素。
getBlasDeviceAddress(uint32_t blasId)
该函数返回 blasId 索引处的底层加速结构的设备内存地址句柄
和往常使用 Vulkan 一样,我们需要对于之前创建的对象在 HelloVulkan::destroyResources 结尾销毁。
// #VKRay
m_rtBuilder.destroy();
5.2.1 帮助类细节:RaytracingBuilder::buildTlas()¶
作为 nvpro-samples 的一部分,该帮助类提供用于构建构建顶层加速结构并且使用一批 Instance (实体)对象来创建一个顶层加速结构。
我们首先创建一个命令缓存并且将 flags 的默认值在这里显示出来。
// 使用一批实体创建顶层加速结构
// - 注意instances的类型(一批实体)
// - 创建的顶层加速结构的结果将会存储在m_tlas
// - 对于顶层加速结构的更新就是使用新的变换矩阵重新构建顶层加速结构
void buildTlas(const std::vector<VkAccelerationStructureInstanceKHR>& instances,
VkBuildAccelerationStructureFlagsKHR flags = VK_BUILD_ACCELERATION_STRUCTURE_PREFER_FAST_TRACE_BIT_KHR,
bool update = false)
{
// 除非要更新顶层加速结构否则buildTlas函数只能调用一次
assert(m_tlas.accel == VK_NULL_HANDLE || update);
uint32_t countInstance = static_cast<uint32_t>(instances.size());
// 用于创建顶层加速结构的命令缓存
nvvk::CommandPool genCmdBuf(m_device, m_queueIndex);
VkCommandBuffer cmdBuf = genCmdBuf.createCommandBuffer();
之后,我能需要将实体们加载进设备中。
// 用于创建顶层加速结构的命令缓存
nvvk::CommandPool genCmdBuf(m_device, m_queueIndex);
VkCommandBuffer cmdBuf = genCmdBuf.createCommandBuffer();
// 创建一个缓存用于存放该批实体数据用于加速结构的构建
nvvk::Buffer instancesBuffer; // 该批的实体缓存中包含每个实体的变换矩阵和底层加速结构的ID
instancesBuffer = m_alloc->createBuffer(cmdBuf, instances,
VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT
| VK_BUFFER_USAGE_ACCELERATION_STRUCTURE_BUILD_INPUT_READ_ONLY_BIT_KHR);
NAME_VK(instancesBuffer.buffer);
VkBufferDeviceAddressInfo bufferInfo{VK_STRUCTURE_TYPE_BUFFER_DEVICE_ADDRESS_INFO, nullptr, instancesBuffer.buffer};
VkDeviceAddress instBufferAddr = vkGetBufferDeviceAddress(m_device, &bufferInfo);
// 插入一个栅栏用于确保在开始构建加速结构之前实体数据的缓存拷贝已经完成(注意下面的备注)
VkMemoryBarrier barrier{VK_STRUCTURE_TYPE_MEMORY_BARRIER};
barrier.srcAccessMask = VK_ACCESS_TRANSFER_WRITE_BIT;
barrier.dstAccessMask = VK_ACCESS_ACCELERATION_STRUCTURE_WRITE_BIT_KHR;
vkCmdPipelineBarrier(cmdBuf, VK_PIPELINE_STAGE_TRANSFER_BIT, VK_PIPELINE_STAGE_ACCELERATION_STRUCTURE_BUILD_BIT_KHR,
0, 1, &barrier, 0, nullptr, 0, nullptr);
插入一个栅栏用于确保在开始构建加速结构之前实体数据的缓存拷贝已经完成
在调用 m_alloc->createBuffer 时会进行两步任务
创建缓存
使用命令缓存将外部数据拷贝至缓存中(使用
vkCmdCopyBuffer)
所以这里在之后需要插入一个栅栏,用于确保数据已经复制拷贝完成再进行接下来的任务。
此时我们已经有两一个命令缓存( cmdBuf ),实体数量( countInstance )和存有所有 VkAccelerationStructureInstanceKHR 数据的缓存地址。有了这些信息,我们就可以调用顶层加速结构构建函数了,该函数将会分配一个暂付缓存,该暂付缓存将会在所有工作结束后销毁。
// 创建顶层加速结构
nvvk::Buffer scratchBuffer;
cmdCreateTlas(cmdBuf, countInstance, instBufferAddr, scratchBuffer, flags, update, motion);
// 最后销毁临时数据
genCmdBuf.submitAndWait(cmdBuf); // 内部会等待任务执行结束
m_alloc->finalizeAndReleaseStaging();
m_alloc->destroy(scratchBuffer);
m_alloc->destroy(instancesBuffer);
}
接下来开始构建真正的顶层加速结构
//--------------------------------------------------------------------------------------------------
// 创建顶层加速结构
//
void nvvk::RaytracingBuilderKHR::cmdCreateTlas(VkCommandBuffer cmdBuf,
uint32_t countInstance,
VkDeviceAddress instBufferAddr,
nvvk::Buffer& scratchBuffer,
VkBuildAccelerationStructureFlagsKHR flags,
bool update,
bool motion)
{
接下来就是填充创建顶层加速结构的结构体。该加速结构用于表示一个包含很多实体的几何体。
该加速结构用于表示一个包含很多实体的几何体
创建和构建顶层加速结构其实和构建底层加速结构区别不大,与底层加速结构的主要区别是:底层加速结构的几何信息是真的几何信息,而顶层加速结构的几何信息是实体信息。
// 将之前拷贝上传的实体设备内存进行设置打包
VkAccelerationStructureGeometryInstancesDataKHR instancesVk{VK_STRUCTURE_TYPE_ACCELERATION_STRUCTURE_GEOMETRY_INSTANCES_DATA_KHR};
instancesVk.data.deviceAddress = instBufferAddr;
// 将instancesVk设置到VkAccelerationStructureGeometryKHR中. 我们需要将实体数据放入联合体中并指定该数据为实体数据(见下面的备注详情)
VkAccelerationStructureGeometryKHR topASGeometry{VK_STRUCTURE_TYPE_ACCELERATION_STRUCTURE_GEOMETRY_KHR};
topASGeometry.geometryType = VK_GEOMETRY_TYPE_INSTANCES_KHR;
topASGeometry.geometry.instances = instancesVk;
// 获取加速结构大小
VkAccelerationStructureBuildGeometryInfoKHR buildInfo{VK_STRUCTURE_TYPE_ACCELERATION_STRUCTURE_BUILD_GEOMETRY_INFO_KHR};
buildInfo.flags = flags;
buildInfo.geometryCount = 1;
buildInfo.pGeometries = &topASGeometry;
buildInfo.mode = update ? VK_BUILD_ACCELERATION_STRUCTURE_MODE_UPDATE_KHR : VK_BUILD_ACCELERATION_STRUCTURE_MODE_BUILD_KHR;
buildInfo.type = VK_ACCELERATION_STRUCTURE_TYPE_TOP_LEVEL_KHR;
buildInfo.srcAccelerationStructure = VK_NULL_HANDLE;
VkAccelerationStructureBuildSizesInfoKHR sizeInfo{VK_STRUCTURE_TYPE_ACCELERATION_STRUCTURE_BUILD_SIZES_INFO_KHR};
vkGetAccelerationStructureBuildSizesKHR(m_device, VK_ACCELERATION_STRUCTURE_BUILD_TYPE_DEVICE_KHR, &buildInfo,
&countInstance, &sizeInfo);
我们需要将实体数据放入联合体中并指定该数据为实体数据
对于
实体数据放入联合体中:instancesVk.data.deviceAddress = instBufferAddr
主要是指上面这行代码,将实体数据
instBufferAddr设置到instancesVk.data.deviceAddress中。而在Vulkan标准中instancesVk.data的类型为VkDeviceOrHostAddressConstKHR,声明如下:// 由VK_KHR_acceleration_structure提供 typedef union VkDeviceOrHostAddressConstKHR { VkDeviceAddress deviceAddress; const void* hostAddress; } VkDeviceOrHostAddressConstKHR;
可以看到该结构体被声明为
union联合体(Vulkan光追标准中很多相关的结构体都是联合体)。对于
指定该数据为实体数据:topASGeometry.geometryType = VK_GEOMETRY_TYPE_INSTANCES_KHR;
主要是指上面这行代码,用于告诉
Vulkan驱动,将数据解析成实体数据。
现在我们就可以创建加速结构了,目前还没到构建阶段。
VkAccelerationStructureCreateInfoKHR createInfo{VK_STRUCTURE_TYPE_ACCELERATION_STRUCTURE_CREATE_INFO_KHR};
createInfo.type = VK_ACCELERATION_STRUCTURE_TYPE_TOP_LEVEL_KHR;
createInfo.size = sizeInfo.accelerationStructureSize;
m_tlas = m_alloc->createAcceleration(createInfo);
NAME_VK(m_tlas.accel);
NAME_VK(m_tlas.buffer.buffer);
构建顶层加速结构同样需要暂付缓存。
// 分配暂付缓存
scratchBuffer = m_alloc->createBuffer(sizeInfo.buildScratchSize,
VK_BUFFER_USAGE_STORAGE_BUFFER_BIT | VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT);
VkBufferDeviceAddressInfo bufferInfo{VK_STRUCTURE_TYPE_BUFFER_DEVICE_ADDRESS_INFO, nullptr, scratchBuffer.buffer};
VkDeviceAddress scratchAddress = vkGetBufferDeviceAddress(m_device, &bufferInfo);
NAME_VK(scratchBuffer.buffer);
最后我们就可以构建该顶层加速结构了。
// 更新构建信息
buildInfo.srcAccelerationStructure = VK_NULL_HANDLE;
buildInfo.dstAccelerationStructure = m_tlas.accel;
buildInfo.scratchData.deviceAddress = scratchAddress;
// 构建偏移信息: 实体数量(其实设置的是VkAccelerationStructureBuildRangeInfoKHR::primitiveCount信息)
VkAccelerationStructureBuildRangeInfoKHR buildOffsetInfo{countInstance, 0, 0, 0};
const VkAccelerationStructureBuildRangeInfoKHR* pBuildOffsetInfo = &buildOffsetInfo;
// 构建顶层加速结构
vkCmdBuildAccelerationStructuresKHR(cmdBuf, 1, &buildInfo, &pBuildOffsetInfo);
}
5.3 main¶
在 main 函数中,我现在可以在初始化光追之后增加对于几何实体和加速结构的创建了。
// #VKRay
helloVk.initRayTracing();
helloVk.createBottomLevelAS();
helloVk.createTopLevelAS();
6 光线追踪描述符集(Descriptor Set)¶
与光栅化着色器一样,光线追踪着色器同样使用描述符集来引用外部资源。在光栅化图形管线中使用不同的材质绘制场景,我们可以根据材质来组织要绘制的对象,并根据材质的使用情况确定渲染顺序。只有当材质要绘制物体时才需要绑定对应的材质管线和描述符。
然而,在光线追踪时,不可能事先知道哪些物体会和光线相交,所以在任意时刻都有可能调用某个着色器。为此 Vulkan 光追扩展使用单独的描述符集集合来描述场景渲染时所需的所有资源。比如,它可能包含所有材质需要的所有纹理。此外加速结构中只存有位置数据,我们需要将顶点和索引缓存传入到着色器中,
这样我们就可以获取到其他的顶点属性。
为了维持光栅化和光线追踪之间的兼容性,我们将会重复利用之前光栅化渲染器的描述符集,该描述符集不仅会包含场景信息,此外还会增加另外一些描述符集用于引用顶层加速结构和缓存输出结果。
在 hello_vulkan.h 头文件中,我们声明与的描述符集相关的对象:
void createRtDescriptorSet();
nvvk::DescriptorSetBindings m_rtDescSetLayoutBind;
VkDescriptorPool m_rtDescPool;
VkDescriptorSetLayout m_rtDescSetLayout;
VkDescriptorSet m_rtDescSet;
光线生成着色器( Ray Generation shader )将会通过代用 TraceRayEXT() 来访问加速结构,在该文档的后面,我们也将使用最近命中着色器( Closest Hit shader )来访问加速结构,输出的图片将会通过光栅化离屏输出,并且只有光线生成着色器可以写入。
离屏输出
离屏输出意思是,输出的图片不与屏幕或者窗口有直接联系,图片也不会直接输出到屏幕上,一般输出的图片为用户自己创建的图片,需要将该图片拷贝至与窗口或屏幕相关的图片上才能显示。
//--------------------------------------------------------------------------------------------------
// 该描述符集包含加速结构和输出图片
//
void HelloVulkan::createRtDescriptorSet()
{
m_rtDescSetLayoutBind.addBinding(RtxBindings::eTlas, VK_DESCRIPTOR_TYPE_ACCELERATION_STRUCTURE_KHR, 1,
VK_SHADER_STAGE_RAYGEN_BIT_KHR); // 顶层加速结构
m_rtDescSetLayoutBind.addBinding(RtxBindings::eOutImage, VK_DESCRIPTOR_TYPE_STORAGE_IMAGE, 1,
VK_SHADER_STAGE_RAYGEN_BIT_KHR); // 输出图片
m_rtDescPool = m_rtDescSetLayoutBind.createPool(m_device);
m_rtDescSetLayout = m_rtDescSetLayoutBind.createLayout(m_device);
VkDescriptorSetAllocateInfo allocateInfo{VK_STRUCTURE_TYPE_DESCRIPTOR_SET_ALLOCATE_INFO};
allocateInfo.descriptorPool = m_rtDescPool;
allocateInfo.descriptorSetCount = 1;
allocateInfo.pSetLayouts = &m_rtDescSetLayout;
vkAllocateDescriptorSets(m_device, &allocateInfo, &m_rtDescSet);
VkAccelerationStructureKHR tlas = m_rtBuilder.getAccelerationStructure();
VkWriteDescriptorSetAccelerationStructureKHR descASInfo{VK_STRUCTURE_TYPE_WRITE_DESCRIPTOR_SET_ACCELERATION_STRUCTURE_KHR};
descASInfo.accelerationStructureCount = 1;
descASInfo.pAccelerationStructures = &tlas;
VkDescriptorImageInfo imageInfo{{}, m_offscreenColor.descriptor.imageView, VK_IMAGE_LAYOUT_GENERAL};
std::vector<VkWriteDescriptorSet> writes;
writes.emplace_back(m_rtDescSetLayoutBind.makeWrite(m_rtDescSet, RtxBindings::eTlas, &descASInfo));
writes.emplace_back(m_rtDescSetLayoutBind.makeWrite(m_rtDescSet, RtxBindings::eOutImage, &imageInfo));
vkUpdateDescriptorSets(m_device, static_cast<uint32_t>(writes.size()), writes.data(), 0, nullptr);
}
6.1 增加场景的描述符集¶
光线追踪同样也需要访问场景描述信息,我们需要通过修改 createDescriptorSetLayout() 函数将原先这些数据在支持光栅化着色器访问的同时支持光追着色器。光线生成着色器需要访问相机矩阵用于计算光线方向,最近命中着色器需要访问材质,场景的实体,纹理,顶点缓存和索引缓存。尽管顶点和索引缓存目前仅会被光追着色器使用,我们在原本光栅化着色器的基础上增加光追着色器也是符合标准的。
// 相机矩阵
m_descSetLayoutBind.addBinding(SceneBindings::eGlobals, VK_DESCRIPTOR_TYPE_UNIFORM_BUFFER, 1,
VK_SHADER_STAGE_VERTEX_BIT | VK_SHADER_STAGE_RAYGEN_BIT_KHR);
// 物体描述
m_descSetLayoutBind.addBinding(SceneBindings::eObjDescs, VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, 1,
VK_SHADER_STAGE_VERTEX_BIT | VK_SHADER_STAGE_FRAGMENT_BIT | VK_SHADER_STAGE_CLOSEST_HIT_BIT_KHR);
// 纹理
m_descSetLayoutBind.addBinding(SceneBindings::eTextures, VK_DESCRIPTOR_TYPE_COMBINED_IMAGE_SAMPLER, nbTxt,
VK_SHADER_STAGE_FRAGMENT_BIT | VK_SHADER_STAGE_CLOSEST_HIT_BIT_KHR);
原本顶点缓存和索引缓存只在光栅化管线中使用,光追踪中这些缓存将会用于存储缓存,所以在分配缓存时设置支持存储功能。此外由于这些缓存将会被加速结构构建器所访问,这种访问需要获取到缓存的原始设备地址(在 VkAccelerationStructureGeometryTrianglesDataKHR 中),所以创建该缓存时也需要附上 VK_BUFFER_USAGE_ACCELERATION_STRUCTURE_BUILD_INPUT_READ_ONLY_BIT_KHR 功能位域。
我们通过更新 loadModel 中的缓存使用来达到此目的:
VkBufferUsageFlags flag = VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT;
VkBufferUsageFlags rayTracingFlags = // 同样也用于构建加速结构
flag | VK_BUFFER_USAGE_ACCELERATION_STRUCTURE_BUILD_INPUT_READ_ONLY_BIT_KHR | VK_BUFFER_USAGE_STORAGE_BUFFER_BIT;
model.vertexBuffer = m_alloc.createBuffer(cmdBuf, loader.m_vertices, VK_BUFFER_USAGE_VERTEX_BUFFER_BIT | rayTracingFlags);
model.indexBuffer = m_alloc.createBuffer(cmdBuf, loader.m_indices, VK_BUFFER_USAGE_INDEX_BUFFER_BIT | rayTracingFlags);
model.matColorBuffer = m_alloc.createBuffer(cmdBuf, loader.m_materials, VK_BUFFER_USAGE_STORAGE_BUFFER_BIT | flag);
model.matIndexBuffer = m_alloc.createBuffer(cmdBuf, loader.m_matIndx, VK_BUFFER_USAGE_STORAGE_BUFFER_BIT | flag);
缓存数组
每一个模型( OBJ )都是由顶点、索引和材质缓存构成的。因此一个场景有一系列这样的缓存。在着色器中我们通过使用实体的 ObjectID 来获取到正确的缓存。
这对于光追来说很方便,我们可以以此来访问光追场景中的所有数据。
6.2 描述符更新¶
和光栅化描述符集一样,光追描述符集也需要当内容放生改变时进行更新,特别是在窗口大小发生改变、输出图片发生了重新创建并且需要重新链接进描述符集。通过在 HelloVulkan 类
中增加一个新成员函数来达到更新描述符集的目的。
void updateRtDescriptorSet();
该函数的实现非常直接,仅仅更新输出图片的引用:
//--------------------------------------------------------------------------------------------------
// 将输出图片更新到描述符集中
// - 当窗口分辨率发生了改变
//
void HelloVulkan::updateRtDescriptorSet()
{
// (1) 设置输出纹理
VkDescriptorImageInfo imageInfo{{}, m_offscreenColor.descriptor.imageView, VK_IMAGE_LAYOUT_GENERAL};
VkWriteDescriptorSet wds = m_rtDescSetLayoutBind.makeWrite(m_rtDescSet, RtxBindings::eOutImage, &imageInfo);
vkUpdateDescriptorSets(m_device, 1, &wds, 0, nullptr);
}
备注
我们使用 nvvk::DescriptorSetBindings 来辅助创建描述符集。这将会避免很多重复性代码和潜在错误。
之后在 onResize 函数(窗口大小发生了改变)中调用该更新函数
updateRtDescriptorSet();
当程序被关闭时我们需要在 destroyResources 函数中销毁本章节创建的资源
vkDestroyDescriptorPool(m_device, m_rtDescPool, nullptr);
vkDestroyDescriptorSetLayout(m_device, m_rtDescSetLayout, nullptr);
6.3 main¶
在 main 函数中,我们将在其他光追调用之后开始创建描述符集。
helloVk.createRtDescriptorSet();
7 光线追踪管线¶
就像前面说的,当进行光线追踪时,不能像光栅化那样,我们不能按照材质组织渲染,所以,所有的的着色器都必须在光追的任意时刻都是有效可执行的,并且具体哪个着色器在执行是在设备运行时动态确定的。
接下来两个章节最主要的目的就是介绍使用着色器绑定表( Shader Binding Table 简称 SBT):该结构使得运行时选择着色器成为可能。该结构的本质是着色器句柄表(也许存储着设备地址),有点
类似于 C++ 的虚函数表,但是这张表是需要我们自己构建(用户也可以通过使用 shaderRecordEXT ,以此在着色器绑定表中携带更多信息),建表步骤如下:
像平常一样将需要的着色器加载、编译到
VkShaderModule中将这些
VkShaderModule打包到VkPipelineShaderStageCreateInfo数组中创建一个
VkRayTracingShaderGroupCreateInfoKHR数组,数组中的每一个VkRayTracingShaderGroupCreateInfoKHR最终都会成为一个着色器绑定表的入口。此时通过数组的索引从着色器组中区分各自的着色器,此时还没有分配设备内存地址。通过
vkCreateRayTracingPipelineKHR将上述的两个数组编译成一个光线追踪管线管线编译时会根据
VkPipelineShaderStageCreateInfo数组的索引将对应的着色器句柄存入一个数组中。该数组可以通过vkGetRayTracingShaderGroupHandlesKHR获取。创建一个带有
VK_BUFFER_USAGE_SHADER_BINDING_TABLE_BIT_KHR功能位域的缓存,并将句柄拷贝到该缓存中。
相比于光栅化图形管线,光线追踪管线的行为更像计算着色器。光追的激发维度是在一个虚拟的长宽高三维空间中,追踪结果使用 imageStore 手动写入。与激发计算管线使用本地组( local group )不同,对于光追需要激发单独的着色器调用。光线追踪的入口为:
光线生成着色器(
ray generation shader),对于每一个像素我们都会调用光线生成着色器。这将会从相机的位置出发,以像素处按照相机镜头评估出一个光线方向。这之后将会调用traceRayEXT()函数往场景中发射光线。traceRayEXT()将会调用下文的各类着色器,这些着色器将会使用光追负载传达结果。
光追负载
光追负载一般是指着色器中使用了 rayPayloadEXT 或 rayPayloadInEXT 关键字声明的变量,相关介绍下文也有,这里给出一个示例。
struct hitPayload
{
vec3 hitValue;
};
layout(location = 0) rayPayloadInEXT hitPayload prd;
layout(location = 1) rayPayloadEXT bool isShadowed;
光追负载被声明作为 rayPayloadEXT 或 rayPayloadInEXT 关键字的变量,同时其构成了着色器之间调用与被调用的关系。每一个着色器的执行都会将其
自身本地声明的 rayPayloadEXT 变量拷贝一份,当调用 traceRayEXT() 调用其他着色器时,调用者可以选择自身的其中一个负载,使得被调用着色器通
过 rayPayloadInEXT 可以访问到调用者所分享的负载( 多称为 输入负载 )。
负载需要明确声明,否则将会导致 SM 的并行占用率随着内存使用过多而降低。
SM
这里的 SM 应该是指流式多处理器( Stream Multi-processor ,简写为 SM ),是构建整个 GPU 的核心模块,一个流式多处理器上一般同时运行多个线程块。每个流式多处理器可以视为具有较小结构的 CPU ,支持指令并行。
SM的占用率是越高越好
接下来需要如下两个类型的的着色器:
未命中着色器(
miss shader),当没有与任何几何体相交时会调用该着色器。一般用于对环境纹理进行采样或者通过光追负载直接返回一个颜色。最近命中着色器(
closest hit shader),当光线与的几何体相交并且离光线起点最近时会调用该着色器。一般用于计算光照并使用光追负载返回结果。有多少最近相交就有多少最近命中着色器的调用,这与基于物体光栅化渲染时覆盖了多少像素概念相通。
另外还有两个可选着色器类型:
相交着色器(
intersection shader),允许与用户与自定义几何体相交。比如为了按需加载几何体而与几何占位符相交,或者与程序化几何体相交而不需要提前进行细分。使用该着色器将会改变加速结构的构建策略,这一部分已经超出了本教程的范围。 目前我们仅采用该Vulkan光追扩展内置好的光线-三角相交测试,该测试将会返回2个浮点类型坐标值,用于表示位于三角形表面上相交点的(u,v)质心坐标(barycentric coordinates),对于一个由点v0,v1,v2构成的三角形, 质心坐标用于定义该交点相对于三角形三个顶点的权重:

质心坐标与交点坐标
一般获取到质心坐标之后需要计算出所在三角形上的交点坐标,该交点坐标计算可参考如下:
hitAttributeEXT vec2 attribs; // 质心坐标
const vec3 barycentrics = vec3(1.0 - attribs.x - attribs.y, attribs.x, attribs.y); // 计算质心权重
const vec3 pos = v0.pos * barycentrics.x + v1.pos * barycentrics.y + v2.pos * barycentrics.z; // 计算交点坐标
任意命中着色器(
any hit shader),在每一个可能的交点处执行。当查找与光线原点最近的交点的过程中可能会发现几个候选交点。任意命中着色器经常用于高效的透明测试,如果透明测试失败,光线可以继续遍历而不需要再次调用traceRayEXT(),内置的任意命中着色器 只是简单的将交点返回给遍历引擎,用于确定哪一个交点是最近的那一个交点。对于本教程,由于我们在构建加速结构时设置了不透明VK_GEOMETRY_OPAQUE_BIT_KHR位域( 5.1 底层加速结构 ),任意命中着色器将永远都不会调用。
候选交点
根据 Vulkan标准文档 9.19. Any-Hit Shaders 中的说明,在相交着色器返回位于光路长度 [t min,t max] 之内的交点时将会执行任意命中着色器。换句话就是,当光线穿透几何体时 有可能会有多个交点。
任意命中着色器主要用于筛选相交着色器返回的交点的。

光线追踪管线¶
我们将从使用三个主要着色器开始:一个光线生成着色器,一个未命中着色器和由一个最近命中着色器构成的一个命中组。这在 GLSL 编译成 SPIR-V 时已经完成。 SPIR-V 的着色器们将会链接成一个能够通过求交计算执行正确的击中着色器的光线追踪管线。
为了专注于创建管线,我们提供了一些简单的着色器。
7.1 增加着色器¶
下载光线追踪着色器
将着色器下载下来并且解压到 src/shaders 。之后返回 CMake 中再次发布工程,相应的着色器文件将会增加到工程中。
着色器下载
在 2 配置环境 章节中,通过 git clone --recursive 指令克隆的项目里已经自带着色器文件,不需要再另外单独下载。
目前 shaders 文件夹下与光追有关了的着色器文件有三种:
raytrace.rgen包含光线生成程序。其同时也声明访问输出缓存image和绑定的VkAccelerationStructureKHR光追加速结构topLevelAS。对于此时该着色器仅仅向输出缓存中写入一个固定颜色。raytrace.rmiss用于定义未命中着色器。当没有几何体与光线相交时,该着色器将会被调用,并且会往光追负载rayPayloadInEXT中写入一个固定颜色。由于我们目前的光线生成程序现在不会追踪任何光线,该未命中着色器将不会被调用。raytrace.rchit包含一个非常简单的最近命中着色器。其将在光线击中几何体(三角形)时被调用。与未命中着色器相同,其也会使用光追负载rayPayloadInEXT。此外该着色器还有另外一个交点属性输入hitAttributeEXT( 也就是质心坐标 )作为内置的光线-三角形相交测试结果。目前 该着色器仅仅往光追负载中写入一个固定颜色。
在头文件中,增加用于构建光线追踪管线的函数,并且增加用于存储管线的成员变量:
void createRtPipeline();
std::vector<VkRayTracingShaderGroupCreateInfoKHR> m_rtShaderGroups;
VkPipelineLayout m_rtPipelineLayout;
VkPipeline m_rtPipeline;
管线同样也会使用常量推送( push constants )存储全局变量,即背景颜色和光源信息。一旦我们在 host 端( CPU )设置了相关数据并在设备中使用,数据的结构声明在 shaders/host_device.h 文件中。
常量推送
常量推送( push constants ),一般用于直接向着色器中推送数据,虽然叫常量推送,但每次推送的数据是可以变化的,该推送方式比传统的描述符集推送方便不少,但方便的代价是常量推送可推送的数据大小有限制(一般都比较小)。比如 NVIDIA GeForce RTX 3070 桌面版的显卡设备支持的最大常量推送大小为 256 字节。
// Push constant structure for the ray tracer
struct PushConstantRay
{
vec4 clearColor;
vec3 lightPosition;
float lightIntensity;
int lightType;
};
在 HelloVulkan 类中增加一个常量推送成员。
// 用于光线追踪的常量推送
PushConstantRay m_pcRay{};
我们实现光线追踪管线是先从光线生成着色器和未命中着色器开始,然后是最近命中着色器。注意,这个着色器顺序是我们自己定的,该 Vulkan 光追扩展其实在创建管线时设置的着色器顺序可以是随意的。光追着色器的概念是对光栅化管线着色器的延续,在光线追踪中也有类似光栅化着色器的执行顺序和彼此着色器间的数据流通。
所有的着色器都使用 VkPipelineShaderStageCreateInfo 类型组成的 std::vector 数组存储。如前所属,此时,该着色器数组中的索引值将作为着色器的唯一标识。这三个着色器都会使用同样的 main 函数作为入口函数。之后使用 vkCreateShaderModule 从已经编译好着色器代码创建着色器句柄 VkShaderModule 并定义相关着色器阶段。
//--------------------------------------------------------------------------------------------------
// 光线追踪管线: 所有着色器, 光线生成着色器, 最近命中着色器, 未命中着色器
//
void HelloVulkan::createRtPipeline()
{
enum StageIndices
{
eRaygen,
eMiss,
eClosestHit,
eShaderGroupCount
};
// 所有的着色器
std::array<VkPipelineShaderStageCreateInfo, eShaderGroupCount> stages{};
VkPipelineShaderStageCreateInfo stage{VK_STRUCTURE_TYPE_PIPELINE_SHADER_STAGE_CREATE_INFO};
stage.pName = "main"; // 全都使用相同的入口函数
// 光线生成着色器
stage.module = nvvk::createShaderModule(m_device, nvh::loadFile("spv/raytrace.rgen.spv", true, defaultSearchPaths, true));
stage.stage = VK_SHADER_STAGE_RAYGEN_BIT_KHR;
stages[eRaygen] = stage;
// 未命中着色器
stage.module = nvvk::createShaderModule(m_device, nvh::loadFile("spv/raytrace.rmiss.spv", true, defaultSearchPaths, true));
stage.stage = VK_SHADER_STAGE_MISS_BIT_KHR;
stages[eMiss] = stage;
// 击中组 - 最近命中着色器
stage.module = nvvk::createShaderModule(m_device, nvh::loadFile("spv/raytrace.rchit.spv", true, defaultSearchPaths, true));
stage.stage = VK_SHADER_STAGE_CLOSEST_HIT_BIT_KHR;
stages[eClosestHit] = stage;
对应的索引标识将会使用 VkRayTracingShaderGroupCreateInfoKHR 结构体存储。该结构体第一个参数 type 用于表示本结构体中所代表的的着色器组的类型。光线
生成着色器和未命中着色器属于 general 着色器,对应的类型就是 VK_RAY_TRACING_SHADER_GROUP_TYPE_GENERAL_KHR ,并且之后仅设置该结构体的 generalShader 成员变量,其他成员
都设置成 VK_SHADER_UNUSED_KHR 。这种设置同样适用于可调用着色器( callable shaders ),但是本教程并没有使用。在我们的布局下光线生成着色器在第一个( 0 ),之后是未命中着色器( 1 )。
// 着色器组
VkRayTracingShaderGroupCreateInfoKHR group{VK_STRUCTURE_TYPE_RAY_TRACING_SHADER_GROUP_CREATE_INFO_KHR};
group.anyHitShader = VK_SHADER_UNUSED_KHR;
group.closestHitShader = VK_SHADER_UNUSED_KHR;
group.generalShader = VK_SHADER_UNUSED_KHR;
group.intersectionShader = VK_SHADER_UNUSED_KHR;
// 光线生成
group.type = VK_RAY_TRACING_SHADER_GROUP_TYPE_GENERAL_KHR;
group.generalShader = eRaygen;
m_rtShaderGroups.push_back(group);
// 未命中
group.type = VK_RAY_TRACING_SHADER_GROUP_TYPE_GENERAL_KHR;
group.generalShader = eMiss;
m_rtShaderGroups.push_back(group);
如之前所述,求交是使用 3 个着色器配合完成:相交着色器用于计算光线与几何体的相交,之后任意命中着色器在每个候选的相交点上执行,并且最近命中着色器将会在光路上最近的相交点上执行。
这 3 个着色器将会合并到一个击中组中。在本示例中我们的几何体是使用三角形构成的,所以 VkRayTracingShaderGroupCreateInfoKHR 中的 type 参数设置的是 VK_RAY_TRACING_SHADER_GROUP_TYPE_TRIANGLES_HIT_GROUP_KHR 。
我们一开始将 generalShader 设置成 VK_SHADER_UNUSED_KHR。之后我们将 intersectionShader 成员设置成 VK_SHADER_UNUSED_KHR 是应为我能使用硬件设备内置的光追算法代替相交着色器。我们不使用任意命中着色器,这样系统将会使用内置的交点筛选策略,所以
将 anyHitShader 设置成 VK_SHADER_UNUSED_KHR 。接下来我们使用的着色器就是最近命中着色器,通过将 closestHitShader 成员设置成索引值 2 ( 最近命中着色器的索引 ),此时 stages 数组中已经包含光线生成着色器和未命中着色器。
// 最近命中着色器
group.type = VK_RAY_TRACING_SHADER_GROUP_TYPE_TRIANGLES_HIT_GROUP_KHR;
group.generalShader = VK_SHADER_UNUSED_KHR;
group.closestHitShader = eClosestHit;
m_rtShaderGroups.push_back(group);
备注
如果几何数据不是三角形,我们需要将 type 设置成 VK_RAY_TRACING_SHADER_GROUP_TYPE_PROCEDURAL_HIT_GROUP_KHR ,并且需要自定义一个相交着色器。
在创建着色器组之后,我们需要通过管线布局( pipeline layout )来描述管线如何与外部数据交互:
VkPipelineLayoutCreateInfo pipelineLayoutCreateInfo;
首先在布局中增加用于光线追踪着色器的全局数据常量推送:
// 常量推送: 我们希望能够更新着色器使用的常量
VkPushConstantRange pushConstant{VK_SHADER_STAGE_RAYGEN_BIT_KHR | VK_SHADER_STAGE_CLOSEST_HIT_BIT_KHR | VK_SHADER_STAGE_MISS_BIT_KHR,
0, sizeof(PushConstantRay)};
VkPipelineLayoutCreateInfo pipelineLayoutCreateInfo{VK_STRUCTURE_TYPE_PIPELINE_LAYOUT_CREATE_INFO};
pipelineLayoutCreateInfo.pushConstantRangeCount = 1;
pipelineLayoutCreateInfo.pPushConstantRanges = &pushConstant;
如前述所言,管线使用两个描述符集: set=0 用于光追管线( 顶层加速结构和输出图片 ), set=1 用于与光栅化分享数据(场景数据)。
// 描述符集: 一个用于光追, 另一个与光栅化管线分享数据
std::vector<VkDescriptorSetLayout> rtDescSetLayouts = {m_rtDescSetLayout, m_descSetLayout};
pipelineLayoutCreateInfo.setLayoutCount = static_cast<uint32_t>(rtDescSetLayouts.size());
pipelineLayoutCreateInfo.pSetLayouts = rtDescSetLayouts.data();
现在管线布局信息已经完成,之后就可以创建布局本身了。
vkCreatePipelineLayout(m_device, &pipelineLayoutCreateInfo, nullptr, &m_rtPipelineLayout);
光追管线的创建是不同于经典的(光栅化)图形管线的。在图形管线中我们仅需要简单的将几个可编程阶段(顶点着色器,片元着色器等)塞入管线中即可。而在光追管线中根据场景中激活的着色器数量,光追管线可以包含任意数量的 着色器。
首先我们需要提供所有要使用的着色器:
// 将着色器和递归深度信息存储到光追管线中
VkRayTracingPipelineCreateInfoKHR rayPipelineInfo{VK_STRUCTURE_TYPE_RAY_TRACING_PIPELINE_CREATE_INFO_KHR};
rayPipelineInfo.stageCount = static_cast<uint32_t>(stages.size()); // Stages are shaders
rayPipelineInfo.pStages = stages.data();
之后,我们指引驱动如何将着色器装配成组。一个光线生成着色器或未命中着色器可以自身成组,但是命中组可以由相交着色器、任意命中着色器和最近命中着色器这 3 种着色器组成。
// 当前示例下, m_rtShaderGroups.size() == 3: 我们有一个光线生成着色器组,
// 一个未命中着色器组,和一个最近命中着色器组。
rayPipelineInfo.groupCount = static_cast<uint32_t>(m_rtShaderGroups.size());
rayPipelineInfo.pGroups = m_rtShaderGroups.data();
光线生成着色器和最近命中着色器可以进行光线追踪,使光线追踪成为一个潜在的递归过程。为了底层的 RTX 层能够优化管线我们设置了着色器中最大的递归深度。我们当前的着色器都非常的简单,我们设置递归深度为 1 ,意味着
我们不会进行光追递归( 即最近命中着色器调用 TraceRayEXT() 函数 )。注意,请尽量保持递归深度为最小深度,代之以一个循环函数。
rayPipelineInfo.maxPipelineRayRecursionDepth = 1; // Ray depth
rayPipelineInfo.layout = m_rtPipelineLayout;
vkCreateRayTracingPipelinesKHR(m_device, {}, {}, 1, &rayPipelineInfo, nullptr, &m_rtPipeline);
一旦管线创建完成,我们就可以销毁支持创建的着色器句柄了:
for(auto& s : stages)
vkDestroyShaderModule(m_device, s.module, nullptr);
}
对于管线布局和管线本身将会在程序关闭时销毁回收,因此增加如下代码到 destroyResources 函数中:
vkDestroyPipeline(m_device, m_rtPipeline, nullptr);
vkDestroyPipelineLayout(m_device, m_rtPipelineLayout, nullptr);
7.2 main¶
在 main 函数中,在其他光追函数调用完成之后我们调用管线创建函数:
helloVk.createRtPipeline();
8 着色器绑定表¶
随笔
在 随笔 中的有对 着色器绑定表 较详细的讲解。
在经典的光栅化渲染中,着色器和相应的资源是在绘制具体物体之前就已经绑定好了,之后,其他物体渲染绑定其他着色器和资源,如此这般。但是光线追踪在任意时刻都会与场景中的任意表面相交,此时需要所有的着色器时时刻刻保持有效可用。
着色器绑定表( Shader Binding Table ,简称 SBT )就是光追的“蓝图”。其允许我们选择哪一个光线生成着色器作为入口,选择哪一个未命中着色器在未发生相交时执行,选择哪一个命中着色器组可在每一个实体上执行。这涉及到当创建几何体时创建的实体和着色器组:
对于每一个顶层加速结构中的每一个实体所对应的 hitGroupId ,该值用于计算命中组中实体相对应着色器绑定表的索引。这需要每一个条目跨度计算基于:
PhysicalDeviceRayTracingPipelinePropertiesKHR::shaderGroupHandleSizePhysicalDeviceRayTracingPipelinePropertiesKHR::shaderGroupBaseAlignmentshaderRecordEXT数据的大小,如果用户有提供。(目前示例中不需要)
8.1 句柄¶
着色器绑定表是最多四个数组的集合,用于存储光线追踪管线着色器组句柄,分别对应:光线生成着色器组,未命中着色器组,最近命中着色器组合和可调用着色器组。在本示例中我们将创建一个缓存用于存储前三组数组。就目前,每个着色器类型我们只有一个着色器,所以每个数组中只有一个句柄组成着色器组。
缓存的结构如下所示,之后将会在调用 vkCmdTraceRaysKHR 时使用。
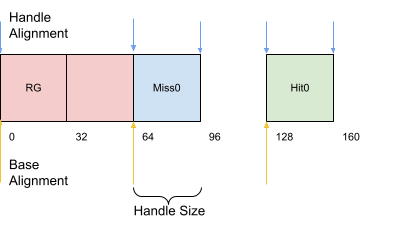
我们需要确保所有组的开头地址都与 shaderGroupBaseAlignment 进行内存对齐,并且组内的每一个元素与 shaderGroupHandleAlignment 进行内存对其。所有组的元素都与 shaderGroupHandleAlignment 进行对其。
内存大小和对齐
特别注意对齐大小和句柄或组大小相对应的。句柄或组大小相应的对齐并不保证一定正确,所以需要向上取整。使用 groupHandleSize 作为内存跨度也许碰巧能够在您的设备上工作,其他设备就不一定了。在一些设备上句柄大小小于对齐大小时,当没有设置相关的内存使用策略将会导致着色器存储( shaderRecordEXT )的数据重叠错位。
向上取整获取下一个对齐位置使用如下算法:
\(alignedSize = [size + (alignment - 1)]\ \texttt{&}\ \texttt{~}(alignment - 1)\).
特例
光线生成着色器组( RayGen )的大小和跨度需要相等。
首先我们在 HelloVulkan 类中增加对于着色器绑定表的创建的函数和缓存的相关声明:
void createRtShaderBindingTable();
nvvk::Buffer m_rtSBTBuffer;
VkStridedDeviceAddressRegionKHR m_rgenRegion{};
VkStridedDeviceAddressRegionKHR m_missRegion{};
VkStridedDeviceAddressRegionKHR m_hitRegion{};
VkStridedDeviceAddressRegionKHR m_callRegion{};
在 createRtShaderBindingTable() 一开始我们收集组相关的信息。对于光线生成着色器总是 1 个也只能是 1 个,所以我们加了一个常数 1 。
//--------------------------------------------------------------------------------------------------
// 着色器绑定表 (SBT)
// - 获取所有的着色器句柄并将其写入着色器绑定表缓存中
// - 除了例外,你总可以像如下代码所示使用。
//
void HelloVulkan::createRtShaderBindingTable()
{
uint32_t missCount{1};
uint32_t hitCount{1};
auto handleCount = 1 + missCount + hitCount;
uint32_t handleSize = m_rtProperties.shaderGroupHandleSize;
之后设置每个组的跨度和大小。除了光线生成组,跨度大小是句柄与 shaderGroupHandleAlignment 对齐的大小。每一个组的大小是元素数量与 shaderGroupBaseAlignment 对齐的结果。
// 着色器绑定表 (缓存) 需要开头的组已经完成对齐并且组中的句柄也已经对齐完成。
uint32_t handleSizeAligned = nvh::align_up(handleSize, m_rtProperties.shaderGroupHandleAlignment);
m_rgenRegion.stride = nvh::align_up(handleSizeAligned, m_rtProperties.shaderGroupBaseAlignment);
m_rgenRegion.size = m_rgenRegion.stride; // pRayGenShaderBindingTable的size成员大小必须与stride(跨度)成员大小相等
m_missRegion.stride = handleSizeAligned;
m_missRegion.size = nvh::align_up(missCount * handleSizeAligned, m_rtProperties.shaderGroupBaseAlignment);
m_hitRegion.stride = handleSizeAligned;
m_hitRegion.size = nvh::align_up(hitCount * handleSizeAligned, m_rtProperties.shaderGroupBaseAlignment);
pRayGenShaderBindingTable
指的是 vkCmdTraceRaysKHR 函数中的 const VkStridedDeviceAddressRegionKHR* pRaygenShaderBindingTable 成员:
// 由VK_KHR_ray_tracing_pipeline提供
void vkCmdTraceRaysKHR(
VkCommandBuffer commandBuffer,
const VkStridedDeviceAddressRegionKHR* pRaygenShaderBindingTable,
const VkStridedDeviceAddressRegionKHR* pMissShaderBindingTable,
const VkStridedDeviceAddressRegionKHR* pHitShaderBindingTable,
const VkStridedDeviceAddressRegionKHR* pCallableShaderBindingTable,
uint32_t width,
uint32_t height,
uint32_t depth);
之后获取光追管线中的着色器组句柄。
// 获取着色器组的句柄
uint32_t dataSize = handleCount * handleSize;
std::vector<uint8_t> handles(dataSize);
auto result = vkGetRayTracingShaderGroupHandlesKHR(m_device, m_rtPipeline, 0, handleCount, dataSize, handles.data());
assert(result == VK_SUCCESS);
之后分配一个缓存用于存储句柄数据。注意,创建着色器绑定表缓存需要 VK_BUFFER_USAGE_SHADER_BINDING_TABLE_BIT_KHR 位域。为了追踪光线我们需要着色器绑定表的地址,这需要 VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT 位域。
目前我们没有使用可调用着色器,其值应该为 0 。
其值应该为 0
指的是如下代码中 m_callRegion.size 的值为 0 。
// 分配用于存储着色器绑定表的缓存.
VkDeviceSize sbtSize = m_rgenRegion.size + m_missRegion.size + m_hitRegion.size + m_callRegion.size;
m_rtSBTBuffer = m_alloc.createBuffer(sbtSize,
VK_BUFFER_USAGE_TRANSFER_SRC_BIT | VK_BUFFER_USAGE_SHADER_DEVICE_ADDRESS_BIT
| VK_BUFFER_USAGE_SHADER_BINDING_TABLE_BIT_KHR,
VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT | VK_MEMORY_PROPERTY_HOST_COHERENT_BIT);
m_debug.setObjectName(m_rtSBTBuffer.buffer, std::string("SBT")); // NSight中设置一个调试名称
NSight
是 NVIDIA 推出的一款 GPU 图形计算调试分析工具。和 RenderDoc 属于同级别工具。
接下来,我们获取每一个着色器组的设备地址并存储。
// 获取每组的着色器绑定表
VkBufferDeviceAddressInfo info{VK_STRUCTURE_TYPE_BUFFER_DEVICE_ADDRESS_INFO, nullptr, m_rtSBTBuffer.buffer};
VkDeviceAddress sbtAddress = vkGetBufferDeviceAddress(m_device, &info);
m_rgenRegion.deviceAddress = sbtAddress;
m_missRegion.deviceAddress = sbtAddress + m_rgenRegion.size;
m_hitRegion.deviceAddress = sbtAddress + m_rgenRegion.size + m_missRegion.size;
如下 lambda 表达式将会返回之前获取到的句柄指针。该函数在将句柄数据拷贝至着色器绑定表中使用。
// 用于帮助获取句柄数据
auto getHandle = [&] (int i) { return handles.data() + i * handleSize; };
由于我们的着色器绑定表缓存在 host 端是可访问的,我们将其内存映射出来用于数据拷贝。
在 host 端是可访问
在创建 m_rtSBTBuffer 着色器绑定表缓存时指定了创建支持 VK_MEMORY_PROPERTY_HOST_VISIBLE_BIT 功能的内存。这样该缓存在 host 端(一般指 CPU 端)可以进行读写访问。访问的途径是通过内存映射进行( m_alloc.map() 其内部最终会调用 vkMapMemory() 内存映射函数)。
// 将着色器绑定表缓存映射出来并写入句柄数据
auto* pSBTBuffer = reinterpret_cast<uint8_t*>(m_alloc.map(m_rtSBTBuffer));
uint8_t* pData{nullptr};
uint32_t handleIdx{0};
拷贝光线着色器句柄。即使数据跨度和大小都比较大,我们也只拷贝句柄数据。
// 光线着色器句柄
pData = pSBTBuffer;
memcpy(pData, getHandle(handleIdx++), handleSize);
将拷贝起始位置定位到未命中着色器组的开头并拷贝所有的未命中着色器句柄,我们目前只有一个,但此时的循环可以支持我们增加多个未命中着色器。
// 未命中着色器
pData = pSBTBuffer + m_rgenRegion.size;
for(uint32_t c = 0; c < missCount; c++)
{
memcpy(pData, getHandle(handleIdx++), handleSize);
pData += m_missRegion.stride;
}
同样的方式,拷贝最近命中着色器组中的句柄。
// 最近命中着色器
pData = pSBTBuffer + m_rgenRegion.size + m_missRegion.size;
for(uint32_t c = 0; c < hitCount; c++)
{
memcpy(pData, getHandle(handleIdx++), handleSize);
pData += m_hitRegion.stride;
}
最后回收内存和释放临时资源。
m_alloc.unmap(m_rtSBTBuffer);
m_alloc.finalizeAndReleaseStaging();
}
和其他资源销毁一样,我们在 destroyResources 增加对取着色器绑定表资源的销毁:
m_alloc.destroy(m_rtSBTBuffer);
着色器顺序
没有要求说着色器必须以光线生成着色器、未命中着色器和最近命中着色器的顺序。就目前而言我们也没有必要非要改变顺序,我们构建的着色器绑定表中对应的 0 号元素、 1 号元素和 2 号元素与构建管线时设置的
VkPipelineShaderStageCreateInfo 数组中的的 0 号元素、 1 号元素和 2 号元素相对应。一般来说,着色器绑定表中和顺序并不需要与管线中的着色器顺序相对应。
着色器绑定表的封装
每个组中的元素都可以通过 VkPhysicalDeviceRayTracingPipelinePropertiesKHR 中的数据获得,使用这个结构体中的数据获取信息的好处就是我们不再需要按照指定的顺序获取。其原因已超出本教程的范围,但是我们提供了一个封装类用于将之前的流程自动化。
可以到 nnvk::SBTWrapper 中找到实现。一些额外的示例将会使用该类。
8.2 main¶
在 main 函数中,现在增加着色器绑定表的构建函数调用。
helloVk.createRtShaderBindingTable();
9 光线追踪¶
创建一个记录调用光追着色器的指令函数。首先,头文件中增加如下声明:
void raytrace(const VkCommandBuffer& cmdBuf, const nvmath::vec4f& clearColor);
我们首先绑定管线和相应的管线布局,设置常量推送:
//--------------------------------------------------------------------------------------------------
// 对场景进行光线追踪
//
void HelloVulkan::raytrace(const VkCommandBuffer& cmdBuf, const nvmath::vec4f& clearColor)
{
m_debug.beginLabel(cmdBuf, "Ray trace");
// 初始化常量推送数据
m_pcRay.clearColor = clearColor;
m_pcRay.lightPosition = m_pcRaster.lightPosition;
m_pcRay.lightIntensity = m_pcRaster.lightIntensity;
m_pcRay.lightType = m_pcRaster.lightType;
std::vector<VkDescriptorSet> descSets{m_rtDescSet, m_descSet};
vkCmdBindPipeline(cmdBuf, VK_PIPELINE_BIND_POINT_RAY_TRACING_KHR, m_rtPipeline);
vkCmdBindDescriptorSets(cmdBuf, VK_PIPELINE_BIND_POINT_RAY_TRACING_KHR, m_rtPipelineLayout, 0,
(uint32_t)descSets.size(), descSets.data(), 0, nullptr);
vkCmdPushConstants(cmdBuf, m_rtPipelineLayout,
VK_SHADER_STAGE_RAYGEN_BIT_KHR | VK_SHADER_STAGE_CLOSEST_HIT_BIT_KHR | VK_SHADER_STAGE_MISS_BIT_KHR,
0, sizeof(PushConstantRay), &m_pcRay);
幸好,所有与 VkStridedDeviceAddressRegionKHR 有关的数据都已在 createRtShaderBindingTable() 中创建完成了。
我们终于可以在指令缓存中增加 vkCmdTraceRaysKHR 指令用于激发光线追踪。注意着色器绑定表缓存的地址已经多次提及。这是因为可以将一个着色器绑定表分开存放到多个缓存中,每种类型对应一个缓存:光线生成着色器,未命中着色器,最近命中着色器和可调用着色器(如何拆分已然超出了本教程的范围)。最后面的三个参数等效于激发计算管线的纬度大小,并表示线程的总数。我们希望每一个像素追踪一根射线,激发纬度设置了输出图片的的宽、高和深度值 1 。
vkCmdTraceRaysKHR(cmdBuf, &m_rgenRegion, &m_missRegion, &m_hitRegion, &m_callRegion, m_size.width, m_size.height, 1);
m_debug.endLabel(cmdBuf);
}
选择光线生成着色器
如果你构建的管线中有多个光线生成着色器,则可通过改变设备地址来选择具体的光线生成着色器。
SBTWrapper
如果使用 SBTWrapper 的话,上面得代码可以替换如下:
auto& regions = m_stbWrapper.getRegions();
vkCmdTraceRaysKHR(cmdBuf, ®ions[0], ®ions[1], ®ions[2], ®ions[3], size.width, size.height, 1);
10 开始追踪¶
现在我们已经完成了光线追踪的所有前置设置和构建:加速结构,描述符集,光追管线和着色器绑定表。现在尝试生成渲染图片吧。
10.1 main¶
在 main 函数中,我们将定义一个用于在光栅化和光线追踪之间切换的本地变量。在光线追踪初始化之后增加如下代码:
bool useRaytracer = true;
在同一函数中,在界面上增加一个复选框,用于运行时进行切换。在 ImGui::ColorEdit3() 之后我们增加:
ImGui::Checkbox("Ray Tracer mode", &useRaytracer); // 光栅化和光线追踪之间进行切换
代码往下找,你可以找到一个包含 helloVk.rasterize() 调用的代码块。我们的应用将支持两种渲染模式,所以将代码块替换成如下:
// 渲染场景
if(useRaytracer)
{
helloVk.raytrace(cmdBuf, clearColor);
}
else
{
vkCmdBeginRenderPass(cmdBuf, &offscreenRenderPassBeginInfo, VK_SUBPASS_CONTENTS_INLINE);
helloVk.rasterize(cmdBuf);
vkCmdEndRenderPass(cmdBuf);
}
备注
光线追踪的行为相较于传统的图形渲染任务更像是个基于计算着色器的计算管线,并且不依赖渲染通道( render pass )。
我们现在可以在光栅化和光线追踪之间切换了。然后现在光线追踪的渲染结果仅仅渲染一个灰色图片:最简单的光线生成着色器现在还没有追踪任何光线,所以仅仅返回一个固定颜色。
光栅化 |
光线追踪 |
|
|---|---|---|
|
|
↔ |
|
11 相机矩阵¶
相机矩阵存储在一个 uniform 缓存中并使用 updateUniformBuffer 更新。光线追踪同样会使用该矩阵,所有我们需要将该缓存适配到光追着色器中。
auto uboUsageStages = VK_PIPELINE_STAGE_VERTEX_SHADER_BIT | VK_PIPELINE_STAGE_RAY_TRACING_SHADER_BIT_KHR;
11.1 光线生成( raytrace.rgen )¶
在着色器中我们需要引入外部头文件,所有需要支持 #include 指令的 GLSL 扩展,在着色器中增加如下:
#extension GL_GOOGLE_include_directive : enable
现在是时候丰富光线生成着色器使其可以追踪光线。我们首先在着色器中增加一个 binding 资源绑定声明,这样着色器就可以访问相机矩阵了。
#include "host_device.h"
layout(set = 1, binding = eGlobals) uniform _GlobalUniforms { GlobalUniforms uni; };
Binding
相机缓存之所以绑定在 binding = eGlobals 的位置是与 host_device.h 中声明的绑定位置相对应,其中 eGlobals 为 0 ,对于 set = 1 是因为在 HelloVulkan::createRtPipeline() 中为第二个 pipelineLayoutCreateInfo.pSetLayouts 描述符集(用于光追资源绑定),对应的索引值为 1 。
// host_device.h 中
#define START_BINDING(a) enum a {
#define END_BINDING() }
START_BINDING(SceneBindings)
eGlobals = 0, // 全局uniform包含相机矩阵
eObjDescs = 1, // 访问物体描述
eTextures = 2 // 访问纹理
END_BINDING();
// 用于每一帧的uniform缓存
struct GlobalUniforms
{
mat4 viewProj; // 相机 view * projection
mat4 viewInverse; // 相机view矩阵的逆矩阵
mat4 projInverse; // 相机projection矩阵的逆矩阵
};
// raytrace.rgen 中
layout(set = 1, binding = eGlobals) uniform _GlobalUniforms { GlobalUniforms uni; };
当追踪一条光线时,最近命中着色器或未命中着色器需要返回一些信息给着色器程序用于对一条新的光线激发光线追踪。这是用过使用 rayPayloadEXT 关键字声明光追负载实现的。
由于该负载会被很多着色器使用,我们创建一个通用着色器文件 raycommon.glsl 用于声明通用数据。
该文件仅仅包括一个负载定义:
struct hitPayload
{
vec3 hitValue;
};
我们现在修改 raytrace.rgen ,在其中包含 raycommon.glsl。
#include "raycommon.glsl"
该负载就是使用 rayPayloadEXT 声明的 hitPayload 结构体。
layout(location = 0) rayPayloadEXT hitPayload prd;
着色器的主函数 main 从计算像素的浮点数坐标开始,该坐标被归一化到 \([0,1]\) 之间。 gl_LaunchIDEXT 包含被渲染像素的整数坐标位置,并且 gl_LaunchSizeEXT 包含了当执行 vkCmdTraceRaysKHR 指令时指定的渲染图片维度。
void main()
{
const vec2 pixelCenter = vec2(gl_LaunchIDEXT.xy) + vec2(0.5);
const vec2 inUV = pixelCenter/vec2(gl_LaunchSizeEXT.xy);
vec2 d = inUV * 2.0 - 1.0;
获取该像素的坐标系之后,我们可以使用 view 和 projection 变换的逆矩阵得到光线的起点和方向。
vec4 origin = uni.viewInverse * vec4(0, 0, 0, 1);
vec4 target = uni.projInverse * vec4(d.x, d.y, 1, 1);
vec4 direction = uni.viewInverse * vec4(normalize(target.xyz), 0);
此外,我们为光线提供一些位域和设置:首先,一个位域用于指示所有的几何体都按照不透明物体对待,就像我们创建加速结构时指定不透明那样。同样我们也设定一条光线的潜在相交的最小和最大距离。这个距离在光线超出该范围后提前退出减少光追消耗,一个经典的用例就是计算环境遮罩( ambient occlusion )。
uint rayFlags = gl_RayFlagsOpaqueEXT;
float tMin = 0.001;
float tMax = 10000.0;
现在我们通过调用 traceRayEXT 函数进行追踪光线。对应的参数为:
void traceRayEXT(accelerationStructureEXT topLevel,
uint rayFlags,
uint cullMask,
uint sbtRecordOffset,
uint sbtRecordStride,
uint missIndex,
vec3 origin,
float Tmin,
vec3 direction,
float Tmax,
int payload);
顶层加速结构用于相交查询
rayFlags控制光线追踪的位域8比特的剔除遮罩culling mask,加速结构的每一个实体都会有一个8比特的遮罩。这个实体遮罩将会与该遮罩值按位与,如果结果为0将会忽略该交点。我们没有利用该特性,所以这里我们给0xFF遮罩值,并且帮助类会设置每一个实体的遮罩为0xFF。sbtRecordOffset和sbtRecordStride用于控制每一个实体的hitGroupId(VkAccelerationStructureInstanceKHR::instanceShaderBindingTableRecordOffset)是如何从底层加速结构命中组数组中获取命中组的。由于我们目前只有一个命中组,所以两个都设置成0。其中的细节相当复杂,可以通过阅读 Will Usher's article 了解更多。missIndex表示底层加速结构的未命中着色器组的索引,当没有与任何实体相交时将会调用该索引对应的未命中着色器。光线的起点,最小范围,方向和对打范围。
该着色器中声明的负载位置,本例中
location = 0。这个编译期间的常数建立了rayPayloadInEXT的调用者和被调用关系,使得允许我们可以选择着色器在哪输出。作为traceRayEXT直接的结果执行着色器(被调用者),其中的rayPayloadInEXT参数将会成为traceRayEXT调用者规定的rayPayloadEXT位置别名(alias)。为了能够更好的运行,两个参数都应该是相同的结构体。这允许我们运行时决定着色器的输出往哪里写,这对于逆向光线追踪非常有用处。
traceRayEXT(topLevelAS, // acceleration structure
rayFlags, // rayFlags
0xFF, // cullMask
0, // sbtRecordOffset
0, // sbtRecordStride
0, // missIndex
origin.xyz, // ray origin
tMin, // ray min range
direction.xyz, // ray direction
tMax, // ray max range
0 // payload (location = 0)
);
最后,我们将负载结果写入图片。
imageStore(image, ivec2(gl_LaunchIDEXT.xy), vec4(prd.hitValue, 1.0));
}
光栅化 |
光线追踪 |
|
|---|---|---|
|
|
↔ |
|
rayPayloadEXT 的 locations
location 用于给予 traceRayEXT 负载一个唯一识别号。由于某些原因,你不能仅通过负载名称将其传递给 traceRayEXT (这被认为是 un-GLSL-y )。
location 的范围为一个着色器一次调用。因此,
如果两个不同的着色器链接进入了同一个光追管线,如果这两个着色器的负载使用同一个
location号声明,这两个负载不会互相干扰。如果着色器被递归调用,即使他们的
location号都是一样的,每一次的调用各自的负载都是独立的。这就是为什么光追着色器需要GPU的栈,这对于计算机图形学来说是一个非常新颖的概念。
备注
负载的 location 和描述符集中的 set 和 binding 还有与顶点属性的 location 是不一样的,后者的作用域范围为全局的。
rayPayloadInEXT 的 locations
rayPayloadInEXT 声明的变量同样有一个 location ,因此其也可以作为 traceRayEXT 的负载进行传递。在本示例中,传入调用着色器的负载背身将会成为被调用着色器传入的负载。
备注
对于被调用者的负载和调用者的负载之前并没有要求 location 需要匹配!这与用于连接顶点着色器和片元着色器之间的 in/out 变量有很大的不同。
11.2 未命中着色器(raytrace.miss)¶
为了共享与光线追踪光栅化清屏颜色,我们将会使用常量推送来改变未命中着色器的返回值。常量推送的 PushConstantRay 结构包含很多成员数据,这里我们声明使用该结构体的第一个成员变量 clearColor 。对于其他成员目前还未声明。
#extension GL_GOOGLE_include_directive : enable
#extension GL_EXT_shader_explicit_arithmetic_types_int64 : require
#include "raycommon.glsl"
#include "wavefront.glsl"
layout(location = 0) rayPayloadInEXT hitPayload prd;
layout(push_constant) uniform _PushConstantRay
{
PushConstantRay pcRay;
};
void main()
{
prd.hitValue = pcRay.clearColor.xyz * 0.8;
}
备注
为了区分光栅化和光追渲染结果,返回的背景颜色较深。
12 简单光照¶
当前最近命中着色器仅返回一个固定单色。为了增加一些光照,我们需要介绍一下表面法线这个概念。然而,光追命中点处只能获取到质心坐标,为了得到交点处的法线和其他顶点属性,我们需要在顶点缓存中找到他们,之后使用质心坐标计算相关属性值。这就是为什么我们在创建光追描述符集时将顶点缓存和索引缓存的可访问范围扩展至最近命中着色器。
可访问范围扩展至最近命中着色器
指的是 6.1 增加场景的描述符集 中的如下代码:
m_descSetLayoutBind.addBinding(SceneBindings::eObjDescs, VK_DESCRIPTOR_TYPE_STORAGE_BUFFER, 1,
VK_SHADER_STAGE_VERTEX_BIT | VK_SHADER_STAGE_FRAGMENT_BIT | VK_SHADER_STAGE_CLOSEST_HIT_BIT_KHR);
12.1 最近命中着色器(raytrace.rchit)¶
当我们创建光追描述符集的时候,其中已经包含了几何数据的定义。因此我们可以直接在最近命中着色器中通过 binding = 2 访问顶点缓存和索引缓存。
我们首先在着色器中包含负载定义和 OBJ-Wavefront 数据结构的头文件
#extension GL_EXT_scalar_block_layout : enable
#extension GL_GOOGLE_include_directive : enable
#extension GL_EXT_shader_explicit_arithmetic_types_int64 : require
#extension GL_EXT_buffer_reference2 : require
#include "raycommon.glsl"
#include "wavefront.glsl"
之后按照描述符集布局声明对应的资源
layout(location = 0) rayPayloadInEXT hitPayload prd;
layout(buffer_reference, scalar) buffer Vertices {Vertex v[]; }; // 物体的位置
layout(buffer_reference, scalar) buffer Indices {ivec3 i[]; }; // 三角形的索引
layout(buffer_reference, scalar) buffer Materials {WaveFrontMaterial m[]; }; // 一个物体最终所有的材质
layout(buffer_reference, scalar) buffer MatIndices {int i[]; }; // 每个三角形对应的材质ID
layout(set = 1, binding = eObjDescs, scalar) buffer ObjDesc_ { ObjDesc i[]; } objDesc;
layout(push_constant) uniform _PushConstantRay { PushConstantRay pcRay; };
在 main 函数中, gl_InstanceCustomIndexEXT 用于告诉我们光线和哪一个物体相交了,并且使用 gl_PrimitiveID 可以找到被击中三角形的顶点信息。
void main()
{
// Object data
ObjDesc objResource = objDesc.i[gl_InstanceCustomIndexEXT];
MatIndices matIndices = MatIndices(objResource.materialIndexAddress);
Materials materials = Materials(objResource.materialAddress);
Indices indices = Indices(objResource.indexAddress);
Vertices vertices = Vertices(objResource.vertexAddress);
// Indices of the triangle
ivec3 ind = indices.i[gl_PrimitiveID];
// Vertex of the triangle
Vertex v0 = vertices.v[ind.x];
Vertex v1 = vertices.v[ind.y];
Vertex v2 = vertices.v[ind.z];
根据如下算法计算质心坐标。
const vec3 barycentrics = vec3(1.0 - attribs.x - attribs.y, attribs.x, attribs.y);
世界空间下的坐标可以通过两种方式计算出来,第一种是使用来自最近命中着色器获得的信息获取,如果交点非常非常远的话,这会有一个精度问题。
vec3 worldPos = gl_WorldRayOriginEXT + gl_WorldRayDirectionEXT * gl_HitTEXT;
另一种更加精确的方式是:通过插值计算位置。我们使用当前击中点上所处的矩阵进行计算,这个矩阵是通过使用顶层加速结构和底层加速结构提供的信息计算出来的。
备注
目前我们所有的底层加速结构都没有提供任何矩阵变换,只有顶层加速结构的实体提供了相应的变换矩阵。
// 计算命中点的坐标
const vec3 pos = v0.pos * barycentrics.x + v1.pos * barycentrics.y + v2.pos * barycentrics.z;
const vec3 worldPos = vec3(gl_ObjectToWorldEXT * vec4(pos, 1.0)); // 将坐标变换到世界空间下
相同的算法也可以应用到法线上。
// 在命中点位置计算法线
const vec3 nrm = v0.nrm * barycentrics.x + v1.nrm * barycentrics.y + v2.nrm * barycentrics.z;
const vec3 worldNrm = normalize(vec3(nrm * gl_WorldToObjectEXT)); // 将法线变换到世界空间下
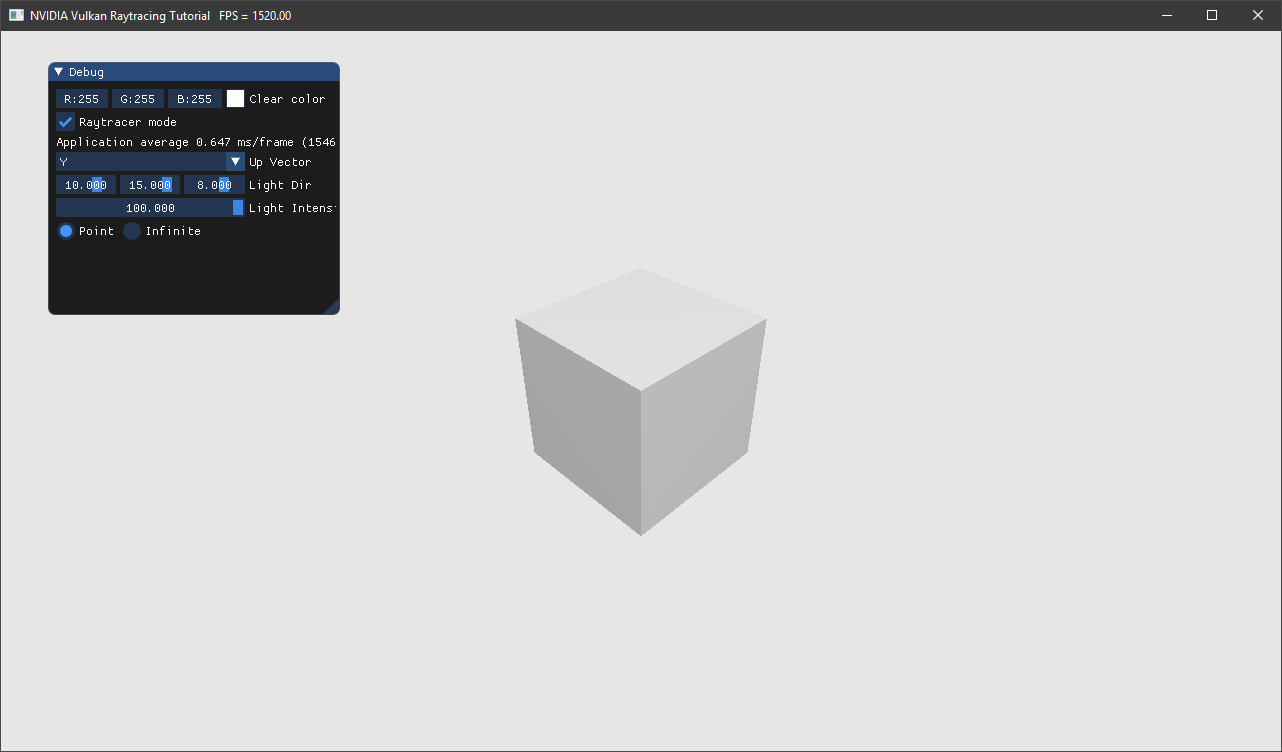
光源目前以一个常量数据呈现,之后可以将法线与光源方向进行点乘得到一个不一样的简单光照效果。
// 光源方向的向量
vec3 L;
float lightIntensity = pcRay.lightIntensity;
float lightDistance = 100000.0;
// 点光源
if(pcRay.lightType == 0)
{
vec3 lDir = pcRay.lightPosition - worldPos;
lightDistance = length(lDir);
lightIntensity = pcRay.lightIntensity / (lightDistance * lightDistance);
L = normalize(lDir);
}
else // 平行光
{
L = normalize(pcRay.lightPosition);
}
13 简单材质¶
基于上面的渲染,我们可以通过增加材质来呈现更有趣的渲染效果。加载进来的 OBJ 对象提供了一个简单的 Alias Wavefront 材质。
Alias Wavefront
估计是指 Alias (原 Alias|Wavefront )是著名的3D软件公司,旗下作品 Maya 、 StudioTools 、等。后来被 Autodesk 公司收购。
Alias Wavefront 应该是 OBJ 模型文件内部的材质数据格式。本人没具体研究过。
13.1 raytrace.rchit¶
该材质使用简单的颜色系数定义基础反射属性,并同时支持纹理。包含该材质的缓存已经在光栅化渲染时创建完成,并且同时也被光追描述符集使用。如下在最近命中着色器中绑定要采样的纹理:
layout(set = 1, binding = eTextures) uniform sampler2D textureSamplers[];
声明的该材质和在光栅化渲染时使用的是一样的,被定义在 wavefront.glsl 中。
定义在 wavefront.glsl 中
wavefront.glsl 会去包含 host_device.h 头文件,材质结构体的定义位于 host_device.h 中。
struct WaveFrontMaterial
{
vec3 ambient;
vec3 diffuse;
vec3 specular;
vec3 transmittance;
vec3 emission;
float shininess;
float ior; // 反射的索引
float dissolve; // 1 == 不透明; 0 == 完全透明
int illum; // 光照模式 (请阅读 http://www.fileformat.info/format/material/)
int textureId;
};
Vertex 结构体中包括材质的索引,我们将使用该索引去对应的缓存中获取相应的材质。
我们首先将 main 函数的结尾处移除如下代码:
float dotNL = max(dot(normal, L), 0.2);
prd.hitValue = vec3(dotNL);
更换成获取材质定义代码:
// 对象的材质
int matIdx = matIndices.i[gl_PrimitiveID];
WaveFrontMaterial mat = materials.m[matIdx];
备注
本示例中每一个对象一个材质,并且可通过索引分别获取到每一个材质。并且每一个三角形都有一个材质索引。
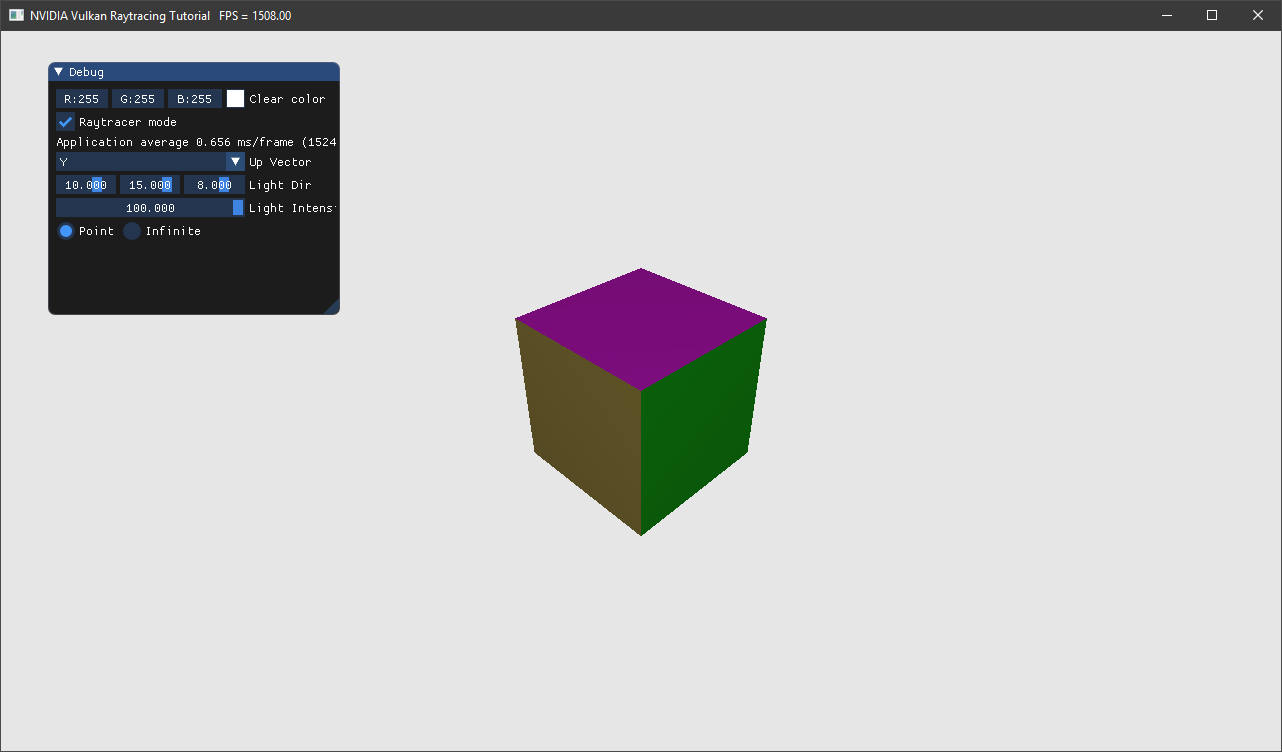
基于此材质定义,我们使用漫反射和高光反射来计算关照。代码同样也支持使用纹理来设置表面反照率。
// 漫反射
vec3 diffuse = computeDiffuse(mat, L, normal);
if(mat.textureId >= 0)
{
uint txtId = mat.textureId + scnDesc.i[gl_InstanceCustomIndexEXT].txtOffset;
vec2 texCoord =
v0.texCoord * barycentrics.x + v1.texCoord * barycentrics.y + v2.texCoord * barycentrics.z;
diffuse *= texture(textureSamplers[nonuniformEXT(txtId)], texCoord).xyz;
}
// 高光反射
vec3 specular = computeSpecular(mat, gl_WorldRayDirectionEXT, L, normal);
最终的光照计算如下:
prd.hitValue = vec3(lightIntensity * (diffuse + specular));
13.2 main¶
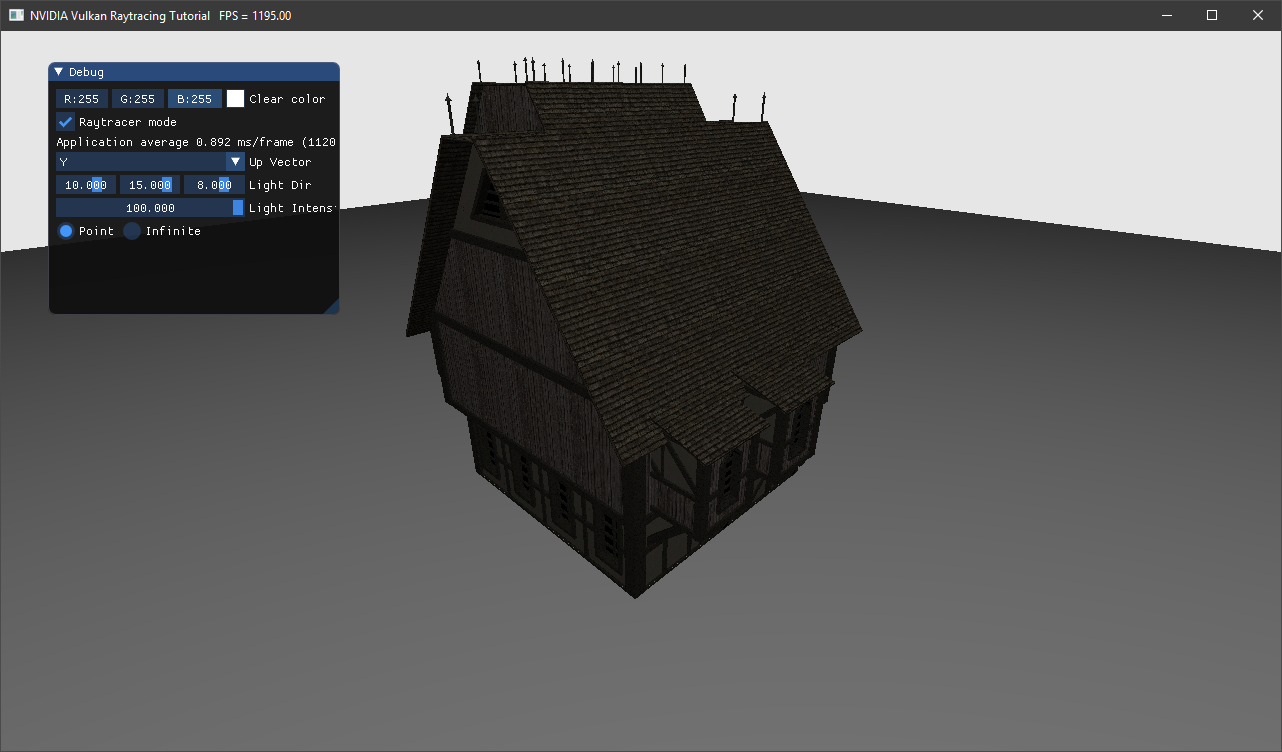
OBJ 的模型是在 main.cpp 中通过调用 helloVk.loadModel 加载的。相比于加载一个方盒子,让我们加载一些更有趣的模型:
helloVk.loadModel(nvh::findFile("media/scenes/Medieval_building.obj", defaultSearchPaths, true));
helloVk.loadModel(nvh::findFile("media/scenes/plane.obj", defaultSearchPaths, true));
由于该模型较大,我们可以将 CameraManip.setLookat 设置成:
CameraManip.setLookat(nvmath::vec3f(4, 4, 4), nvmath::vec3f(0, 1, 0), nvmath::vec3f(0, 1, 0));
14 阴影¶
如上光追渲染能得到一个应用了一些光照的场景,但是目前还没有阴影。在本示例的结尾,我们将会增加一个新的光线类型,并且从最近命中着色器中发射该光线,该新增加的光线类型需要增加一个新的未命中着色器。
14.1 createRaytracingPipeline¶
对于简单的阴影光线我们只需要计算出该光线是否与几何体相交即可。我们可以使用一个布尔( Boolean )负载来指示是否发生了相交,并且使用当新增加的未命中着色器将负载设置成未命中状态。
该压缩文件中只有一个文件 raytraceShadow.rmiss 。将该着色器文件解压并加到 src/shaders 目录下,之后执行 CMake 即可。该着色器文件将会被编译,并且编译的 SPIR-V 目标文件将会和其他 GLSL 文件一道存放到 shaders 文件夹中。
在 createRtPipeline 函数体中,我们需要在之前的未命中着色器之后增加对于新未命中着色器的定义。
enum StageIndices
{
eRaygen,
eMiss,
eMiss2, // 新增未命中着色器
eClosestHit,
eShaderGroupCount
};
并且创建相应的着色器句柄:
// 当阴影光线没有和任何几何体相交的话将会调用第二个未命中着色器。其只是表示未发生遮挡。
stage.module =
nvvk::createShaderModule(m_device, nvh::loadFile("spv/raytraceShadow.rmiss.spv", true, defaultSearchPaths, true));
stage.stage = VK_SHADER_STAGE_MISS_BIT_KHR;
stages[eMiss2] = stage;
之后使用该着色器句柄并将其添加到相应的着色器组中:
// 阴影的未命中着色器
group.type = VK_RAY_TRACING_SHADER_GROUP_TYPE_GENERAL_KHR;
group.generalShader = eMiss2;
m_rtShaderGroups.push_back(group);
现在光追管线可以允许从最近命中着色器发生光线,其中需要将光线追踪的递归次数增加到 2 级。
// 光线追踪可以从相机发射光线,并且阴影光线可以从命中的相交点处发射光线,因此递归级别是2。
// 为了性能考虑这个递归层级越小越好。
// 为了防止过深的递归,在生成光线时光线追踪递归会展成一个循环。
rayPipelineInfo.maxPipelineRayRecursionDepth = 2; // 光线递归深度
资源限制
Vulkan 规范在运行时并不保证进行递归检查。如果在设置光追管线构造信息时设置了超过物理设备支持的递归深度,其结果是未定义的。
KHR 的光追规范中将原本 NV 规范中的最小递归深度 31 降低到了 1 (比如不进行递归)。由于我们现在需要将递归限制在 2 ,我们
需要检查一下设备是否支持该递归深度:
// Spec only guarantees 1 level of "recursion". Check for that sad possibility here.
if (m_rtProperties.maxRayRecursionDepth <= 1) {
throw std::runtime_error("Device fails to support ray recursion (m_rtProperties.maxRayRecursionDepth <= 1)");
}
m_rtProperties 将会在 HelloVulkan::initRayTracing 中进行获取赋值。
14.2 createRtShaderBindingTable¶
新加入的未命中着色器组改变了我们着色器绑定表的结构,现在其结构如下:
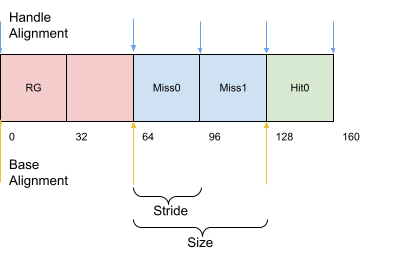
因此我们需要修改 HelloVulkan::createRtShaderBindingTable 函数,指定我们有两个未命中着色器,其中的一个是我们新加入的,另一个是原来的。
uint32_t missCount{2};
14.3 createRtDescriptorSet¶
对于描述符集中的每一个资源,我们需要设置那些着色器阶段可以访问这些资源。由于阴影光线将会从最近命中着色器开始追踪,我们需要增加绑定的加速结构在 VK_SHADER_STAGE_CLOSEST_HIT_BIT_KHR 的最近命中着色器阶段可以被访问:
// 顶层加速结构, 被光线生成着色器和最近命中着色器使用(用于向外发射光线)
m_rtDescSetLayoutBind.addBinding(RtxBindings::eTlas, VK_DESCRIPTOR_TYPE_ACCELERATION_STRUCTURE_KHR, 1,
VK_SHADER_STAGE_RAYGEN_BIT_KHR | VK_SHADER_STAGE_CLOSEST_HIT_BIT_KHR); // TLAS
14.4 raytrace.rchit¶
现在最近命中着色器需要访问加速结构用于发射光线:
layout(set = 0, binding = eTlas) uniform accelerationStructureEXT topLevelAS;
这些光线同样需要携带负载,其需要定义在与当前射线负载不同的位置上。在本示例中,该负载是一个简单的布尔值,用于指示是否发生了遮挡:
layout(location = 1) rayPayloadEXT bool isShadowed;
在着色器的 main 函数中,移除之前简单将负载设置成 prd.hitValue = c; ,此时我们将会发射新的光线。为了选择阴影用的未命中着色器,我们将传递给 traceRayEXT() 的 missIndex 设置成 1 而不是 0 。负载的位置将会与 layout(location = 1) 声明的进行匹配。注意,当我们调用 traceRayEXT() 时我们设置的光追位域如下:
gl_RayFlagsSkipClosestHitShaderKHR:将不会调用最近命中着色器,只会调用未命中着色器gl_RayFlagsOpaqueKHR:将不会调用任意命中着色器,所以所有的对象都是不透明的gl_RayFlagsTerminateOnFirstHitKHR:使用第一个交点就好
由于我们略过了阴影命中着色器组,当击中物体表面时没有代码会执行。所以我们将 isShadowed 负载初始化为 true ,并且将会依靠未命中着色器将该负载设置成 false 来表示没有碰到任何表面。同样我们设置的光追位域来优化光线追踪:因为此阴影光线只需要简单返回是否与表面相交,所以我们可以在获得了第一个交点时就告诉光追引擎停止继续遍历,这避免了执行最近命中着色器。
阴影光线只有在光源位于表面前方时才纳入考量,并且如果我们处在阴影中就不需要计算光照的高光部分(因为光源对于此渲染点是不可见的)。现在基于之前的高光计算部分与阴影相结合:
vec3 specular = vec3(0);
float attenuation = 1;
// 只有表面可见时才进行阴影光线的追踪
if(dot(normal, L) > 0)
{
float tMin = 0.001;
float tMax = lightDistance;
vec3 origin = gl_WorldRayOriginEXT + gl_WorldRayDirectionEXT * gl_HitTEXT;
vec3 rayDir = L;
uint flags =
gl_RayFlagsTerminateOnFirstHitEXT | gl_RayFlagsOpaqueEXT | gl_RayFlagsSkipClosestHitShaderEXT;
isShadowed = true;
traceRayEXT(topLevelAS, // acceleration structure
flags, // rayFlags
0xFF, // cullMask
0, // sbtRecordOffset
0, // sbtRecordStride
1, // missIndex
origin, // ray origin
tMin, // ray min range
rayDir, // ray direction
tMax, // ray max range
1 // payload (location = 1)
);
if(isShadowed)
{
attenuation = 0.3;
}
else
{
// 高光
specular = computeSpecular(mat, gl_WorldRayDirectionEXT, L, normal);
}
}
最终的负载可以按照阴影光线的结果进行调整:
prd.hitValue = vec3(lightIntensity * attenuation * (diffuse + specular));
最终的工程可以在 ray_tracing__simple 文件夹下找到。
15 拓展延伸¶
从此时起,您可以继续创建自己的光线类型和着色器,并尝试更高级的光线跟踪算法。